5 Duomenų filtravimas, rikiavimas ir apjungimas
Duomenų analizėje labai svarbu gebėti efektyviai apdoroti, filtruoti ir sujungti informaciją. Šiame skyriuje susipažinsime su pagrindinėmis R kalbos funkcijomis, kurios padeda ieškoti tam tikras sąlygas atitinkančių elementų, identifikuoti pasikartojančias reikšmes, tvarkyti praleistus reikšmes bei filtruoti duomenų lenteles. Taip pat aptarsime būdus, kaip išrikiuoti vektorius ir lenteles, pertvarkyti duomenų struktūras bei sujungti kelis duomenų šaltinius į vieną.
5.1 Filtravimas
Duomenų filtravimas gali reikšti įvairius veiksmus, skirtus iš duomenų išskirti tik aktualią informaciją. Tai gali būti tam tikras sąlygas tenkinančių elementų atranka, pasikartojančių reikšmių identifikavimas, praleistų duomenų nustatymas ir pašalinimas ar jų tvarkymas.
5.1.1 Sąlygą tenkinančių elementų paieška
Pavyzdžiui funkcija which() nustato, kurio loginio vektoriaus elementų reikšmės lygios TRUE.
| Argumentas | Reikšmė |
|---|---|
x |
loginių reikšmių vektorius arba matrica |
arr.ind |
kai x matrica, nurodo ar grąžinti ieškomos reikšmės numerį |
Paprastu pavyzdžiu iliustruosime funkcijos veikimą - nustatysime, kurios vektoriaus t reikšmės yra lygios TRUE.
Kadangi funkcijos which() pagrindinis argumentas yra loginių reikšmių vektorius arba matrica, tokį vektorių visada galima sukurti sudarant loginę sąlygą.
Logines sąlygas galima apjungti, kadangi kelių loginių sąlygų rezultatas vis vien bus loginių reikšmių vektorius.
Kodas
which(x >= 0 & x <= 10)
#> [1] 1 2 4Jeigu which() funkcija taikoma su loginių reikšmių matrica, patogu naudoti papildomą argumentą arr.ind, kurį naudojant grąžinami sąlygą atitinkantys matricos elementų eilės numeriai.
Kartais tenka surasti mažiausio ar didžiausio vektoriaus elemento numerį. Tam naudojamos specialios funkcijos which.min() ir which.max().
Jei reikia patikrinti, ar tam tikra reikšmė arba visa aibė reikšmių yra vektoriuje (kitoje aibėje), naudojama funkcija match().
| Argumentas | Reikšmė |
|---|---|
x |
ieškoma reikšmė arba jų vektorius |
table |
vektorius, kuriame ieškoma reikšmė x |
Funkcijos match() rezultatas yra pirmojo reikšmę x atitinkančio elemento numeris. Jei ieškomos reikšmės vektoriuje table nėra, grąžinama reikšmė NA.
Kodas
match(x = 1, table = x)
#> [1] NAJei ieškomos elementas x vektoriuje table pasikartoja keliskart, f-ja match() grąžina tik pirmojo iš jų eilės numerį.
Kodas
match(-2, x)
#> [1] 3Funkcijai match() kaip alternatyvą galima naudoti dvejetainį (binarinį) operatorių x %in% table, kuris grąžina loginį vektorių, nurodantį, ar kiekviena x elemento reikšmė randama kitame table vektoriuje (aibėje).
Kodas
x %in% 0:10
#> [1] TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEŠi išraiška patikrina, ar kiekvienas x elementas yra iš reikšmių aibės 0:10, ir grąžina TRUE arba FALSE kiekvienai x pozicijai. Toks binarinis operatorius naudingas, kai reikia atrinkti elementus naudojant logines sąlygas.
Kodas
x[x %in% 0:10]
#> [1] 7 0 4Naudojant funkciją
which(), suraskite numerius tų vektoriausxelementų, kurie lygūs 6 arba -6.Užrašykite komandą, kuri surastų nelyginių vienženklių vektoriaus
xelementų numerius.Sugalvokite būdą, kaip, nenaudojant funkcijos
which.min(), surasti mažiauso vektoriaus elemento numerį.
5.1.2 Pasikartojantys vektoriaus elementai
Pasikartojančių vektoriaus elementų (dublikatų), nustatymui naudojama funkcija duplicated(). Jos rezultatas yra tokio paties ilgio loginis vektorius, kur reikšmė TRUE nurodoma tada, kai elementas pasikartoja. Visų kitų elementų reikšmės lygios FALSE.
Kodas
s <- c("s", "u", "s", "i", "s", "u", "k", "o")
duplicated(s)
#> [1] FALSE FALSE TRUE FALSE TRUE TRUE FALSE FALSEFunkcija anyDuplicated() patikrina, ar bent vienas elementas pasikartoja. Jos rezultatas yra pirmojo pasikartojimo vektoriuje numeris.
Kodas
anyDuplicated(s)
#> [1] 3Matematikoje aibė apibrėžiama kaip aiškiai apibrėžtų, nesikartojančių elementų rinkinys. Norint gauti vektoriaus elementų aibę naudojama funkcija unique(). Jos rezultatas yra pradinis vektorius be pasikartojančių elementų.
Kodas
unique(s)
#> [1] "s" "u" "i" "k" "o"Sugalvoti komandą, kuri į atskirą vektorių išrinktų bent vieną kartą pasikartojančius vektoriaus
selementus.Užrašykite komandą, kuri išrinktų tuos vektoriaus
selementus, kurie neturi pasikartojimų, t. y. reikia gauti vektoriųc("i", "k", "o")
5.1.3 Praleistos reikšmės duomenyse
Dažnu atveju realiuose duomenyse pasitaiko praleistų reikšmių. Standartiškai joms žymėti naudojama speciali konstanta NA.
Turint duomenis vektoriaus ar duomenų lentelės struktūros tipo, visada verta pasitikrinti, kiek tokių reikšmių yra iš viso.
Tai galima padaryti su funkcija summary(). Tai bendro pobūdžio (generic) funkcija, kurios veikimas priklauso nuo jai nurodomo objekto tipo. Pvz., jeigu nurodomas vektorius, tai ši f-ja suskaičiuoja pagrindines duomenų charakteristikas ir pateikia praleistų reikšmių skaičių. Jeigu nurodoma duomenų lentelė, atliekami tie patys skaičiavimai kiekvienam kintamajam atskirai.
Kodas
y <- c(7, -2, 4, NA, 22, 26, 27, -2, 12, -9, NA, 0, 29, 16, -7, 6, 26, 1, 5, 12)
summary(y)
#> Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
#> -9.000 0.250 6.500 9.611 20.500 29.000 2
d <- read.table(header = TRUE, text = "
lytis ugis svoris grupe
vyras 175 76 B
vyras 180 NA B
moteris 170 67 A
moteris 167 64 B
vyras 178 80 A
moteris NA 59 NA
vyras 184 NA A
moteris 171 68 B
moteris 177 70 A
vyras 185 84 B
")
summary(d)
#> lytis ugis svoris grupe
#> Length:10 Min. :167.0 Min. :59.00 Length:10
#> Class :character 1st Qu.:171.0 1st Qu.:66.25 Class :character
#> Mode :character Median :177.0 Median :69.00 Mode :character
#> Mean :176.3 Mean :71.00
#> 3rd Qu.:180.0 3rd Qu.:77.00
#> Max. :185.0 Max. :84.00
#> NA's :1 NA's :2Nustatymui, kurie vektoriaus elementai yra su praleistomis reikšmėmis, taikoma funkcija is.na(). Rezultatas yra loginis vektorius, kurio elementų reikšmė yra TRUE, jei tikrinamo elemento reikšmė NA arba NaN, ir FALSE – kitais atvejais.
Kodas
is.na(y)
#> [1] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
#> [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
is.na(d)
#> lytis ugis svoris grupe
#> [1,] FALSE FALSE FALSE FALSE
#> [2,] FALSE FALSE TRUE FALSE
#> [3,] FALSE FALSE FALSE FALSE
#> [4,] FALSE FALSE FALSE FALSE
#> [5,] FALSE FALSE FALSE FALSE
#> [6,] FALSE TRUE FALSE TRUE
#> [7,] FALSE FALSE TRUE FALSE
#> [8,] FALSE FALSE FALSE FALSE
#> [9,] FALSE FALSE FALSE FALSE
#> [10,] FALSE FALSE FALSE FALSEAtliekant duomenų analizę, pravartu žinoti, kurie duomenų lentelės įrašai neturi praleistų reikšmių. Tam naudojama funkcija complete.cases(), kurios rezultatas yra logininis vektorius: TRUE - jei duomenų lentelės eilutėje nėra praleistų reikšmių, FALSE - jei eilutėje yra bent viena praleista reikšmė.
Kodas
complete.cases(d)
#> [1] TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUEJeigu duomenyse randamos praleistos reikšmės, dažnu atveju jos yra pašalinamos. Paprasčiausias būdas pašalinti praleistas reikšmes iš vektoriaus – jų neįtraukti. Tam tereikia nustatyti, kuriuose indeksuose praleistų reikšmių nėra.
Kodas
i <- !is.na(y)
y[i]
#> [1] 7 -2 4 22 26 27 -2 12 -9 0 29 16 -7 6 26 1 5 12Norint iš duomenų lentelės pašalinti visus įrašus, kuriuose yra bent viena praleista reikšmė, galima naudoti funkcijos complete.cases() rezultatą.
Kodas
i <- complete.cases(d)
d[i, ]
#> lytis ugis svoris grupe
#> 1 vyras 175 76 B
#> 3 moteris 170 67 A
#> 4 moteris 167 64 B
#> 5 vyras 178 80 A
#> 8 moteris 171 68 B
#> 9 moteris 177 70 A
#> 10 vyras 185 84 BTaip pat praleistų reikšmių pašalinimui galima naudoti funkcijas na.exclude() arba na.omit().
Kodas
na.omit(y)
#> [1] 7 -2 4 22 26 27 -2 12 -9 0 29 16 -7 6 26 1 5 12
#> attr(,"na.action")
#> [1] 4 11
#> attr(,"class")
#> [1] "omit"
na.omit(d)
#> lytis ugis svoris grupe
#> 1 vyras 175 76 B
#> 3 moteris 170 67 A
#> 4 moteris 167 64 B
#> 5 vyras 178 80 A
#> 8 moteris 171 68 B
#> 9 moteris 177 70 A
#> 10 vyras 185 84 B
5.1.4 Dar kartą apie funkciją subset()
Skyriuje apie duomenų struktūras trumpai aptarėme kaip galima filtruoti duomenis naudojant elementų indeksus. Toliau išsamiau aptarsime funkcijos subset() taikymą duomenų filtravimui.
Naudojant šią funkciją, loginiai veiksmai su konstanta NA grąžina reikšmę FALSE. Pavyzdžiui, iš lentelės d išrinksime tik B grupės stebinius.
Kodas
subset(d, grupe == "B")
#> lytis ugis svoris grupe
#> 1 vyras 175 76 B
#> 2 vyras 180 NA B
#> 4 moteris 167 64 B
#> 8 moteris 171 68 B
#> 10 vyras 185 84 BKadangi naujai sudarytame duomenų rinkinyje kintamasis grupe turi vienintelę reikšmę B, jis nebereikalingas, todėl galimą kintamąjį išmesti.
Kodas
subset(d, grupe == "B", select = -grupe)
#> lytis ugis svoris
#> 1 vyras 175 76
#> 2 vyras 180 NA
#> 4 moteris 167 64
#> 8 moteris 171 68
#> 10 vyras 185 84Galima nurodyti ir kelis kintamuosius, kuriuos reikia palikti arba išmesti.
Iš eilės einančių pasirenkamų kintamųjų aibę galima nurodyti per dvitaškį užrašant pirmojo ir paskutinio kintamojo vardus.
Kodas
subset(d, grupe == "B", select = lytis:ugis)
#> lytis ugis
#> 1 vyras 175
#> 2 vyras 180
#> 4 moteris 167
#> 8 moteris 171
#> 10 vyras 185Užrašykite komandą, kuri surastų kuriuose duomenų lentelės
deilutėse yra daugiau nei \(80\, kg\) sveriantys vyrai. Turite gauti eilučių numerių vektorių. Jį panaudokite sudarant naują duomenų lentelę.Užrašykite komandą, kuri apskaičiuotų, kiek grupėje B yra moterų.
Iš duomenų lentelės
dišrinkite B grupės moterų stebinius. Užrašykite dvi tokios komandos versijas: naudojant ir nenaudojantsubset()f-jos.Iš duomenų lentelės
mtcarsnustatykite degalų sąnaudas (kintamasismpg) automobilių, kurių variklis turi 4 cilindrus (kintamasiscyl) ir kurių arklio galia (kintamasishp) yra mažesnė nei 100.
5.2 Rikiavimas
Rikiavimas leidžia greičiau pastebėti dėsningumus, atlikti palyginimus ar pasiruošti tolimesnei analizei. Šiame skyriuje apžvelgsime, kaip R aplinkoje galima išrikiuoti vektorius ir duomenų lenteles, taip pat susipažinsime su duomenų pertvarkymo funkcijomis.
5.2.1 Vektoriaus reikšmių rikiavimas
Vektoriaus elementų išrikiavimo priešinga tvarka naudojama funkcija rev().
Vektoriaus reikšmių išrikiavimui nemažėjimo arba nedidėjimo tvarka naudojama funkcija sort().
| Argumentas | Reikšmė |
|---|---|
x |
vektorius |
decreasing |
pagal nutylėjimą FALSE, nurodo, ar rikiuoti nedidėjimo tvarka |
na.last |
pagal nutylėjimą NA, dar galimos reikšmės TRUE arba FALSE
|
Pagal nutylėjimą skaitinio vektoriaus elementai išrikiuojami nemažėjimo tvarka.
Kodas
sort(x)
#> [1] -4.7 -3.2 -1.4 -0.5 1.5 3.8 4.1 5.3 7.7 8.9Nedidėjimo tvarka gaunama pakeičiant argumento decreasing reikšmę į TRUE.
Kodas
sort(x, decreasing = TRUE)
#> [1] 8.9 7.7 5.3 4.1 3.8 1.5 -0.5 -1.4 -3.2 -4.7Argumentas na.last = NA pagal nutylėjimą nurodo, kad rikiuojant NA reikšmės išmetamos. Nurodžius argumento reikšmę TRUE, praleistos reikšmės nukeliamos į išvesties pabaigą, o nurodžius FALSE - į išvesties pradžią.
Rikiuoti galima ne tik skaičius, bet ir raides pagal abėcėlės tvarką.
Ilgesnės simbolių sekos (nebūtinai vienodo ilgio) išrikiuojamos leksikografine tvarka: iš pradžių pagal pirmą žodžio simbolį, tada pagal antrą ir t. t.
Vektoriaus elementų numerius išrikiuotame vektoriuje nustato f-ja order().
| Argumentas | Reikšmė |
|---|---|
... |
vienas ar keli vektoriai |
decreasing |
pagal nutylėjimą FALSE, nurodo, ar rikiuoti nedidėjimo tvarka |
na.last |
pagal nutylėjimą NA, dar galimos reikšmės TRUE arba FALSE
|
Funkcijos order() reikšmė yra vektoriaus elementų perstatinys. Tai reiškia, kad ši funkcija grąžina ne išrikiuotus vektoriaus elementus, o jų numerius.
Pirmojo gauto vektoriaus elemento reikšmė 2 nurodo, kad pirmas tarp išrikiuotų vektoriaus elementų būtų antrasis vektoriaus elementas z[2], kurio reikšmė a. Antrasis elementas lygus 3 ir tai reiškia, kad antras tarp išrikiuotų elementų būtų z[3], kurio reikšmė b. Trečiasis elementas lygus 1, vadinasi trečiasis tarp išrikiuotų elementų būtų z[1], kurio reikšmė lygi c.
Parodysime, kad vektoriaus elementus išdėsčius pagal funkcijos order() grąžinamą numerių vektorių, gaunamas išrikuotas vektorius, kokį gautume su funkcija sort().
Kodas
z[i]
#> [1] "a" "b" "c"Funkcijos order() grąžinamas vektorius naudojamas matricos arba duomenų lentelių eilučių išrikiavimui pagal kurio nors stulpelio reikšmes. Pavyzdžiui, lentelės tyrimas eilutes išrikiuosime pagal kintamąjį X.
Kodas
tyrimas <- read.table(header = TRUE, text = "
X Y Z
b 1.3 TRUE
a 5.2 TRUE
b 2.5 TRUE
c 1.2 FALSE
a 3.8 FALSE
c 2.4 FALSE
")
i <- order(tyrimas$X)
tyrimas[i, ]
#> X Y Z
#> 2 a 5.2 TRUE
#> 5 a 3.8 FALSE
#> 1 b 1.3 TRUE
#> 3 b 2.5 TRUE
#> 4 c 1.2 FALSE
#> 6 c 2.4 FALSELaikantis funkcinio programavimo stiliaus viską galima užrašyti viena išraiška.
Kodas
tyrimas[order(tyrimas$X), ]
#> X Y Z
#> 2 a 5.2 TRUE
#> 5 a 3.8 FALSE
#> 1 b 1.3 TRUE
#> 3 b 2.5 TRUE
#> 4 c 1.2 FALSE
#> 6 c 2.4 FALSEKad funkcijos order() viduje būtų galima tiesiogiai naudoti lentelės kintamųjų pavadinimus, ją galima įkelti į funkciją with(). Tai ypač patogu tuo atveju, kai reikia užrašyti iš karto kelis vienos lentelės kintamuosius.
Eilutes galima išrikiuoti iš karto pagal kelis stulpelius. Pvz., išrikiuosime eilutes kintamojo X didėjimo (abėcėlės) tvarka, bet tuo atveju kai kintamojo X reikšmės sutampa, eilutes išrikiuosime pagal kintamąjį Y.
Funkcija order() sukuria tokį perstatinį, kuris vektoriaus elementus išrikiuoja nemažėjimo tvarka. Jei lentelės eilutes reikia išrikiuoti vektoriaus mažėjimo tvarka, nurodomas parametras decreasing = TRUE. Jei vektorius arba kintamasis, pagal kurį atliekamas rikiavimas, yra skaitinis, paprasčiau pakeisti jo ženklą.
Pvz., išrikiuosime lentelės tyrimas eilutes kintamojo X didėjimo tvarka, bet kintamojo Y mažėjimo tvarka.
Kategoriniams kintamiesiems ženklo pakeisti negalima, todėl tokiais atvejais gali būti naudojama speciali pagalbinė funkcija xtfrm(). Pavyzdžiui, išrikiuosime lentelę kintamojo X mažėjimo tvarka ir kintamojo Y didėjimo tvarka.
Sugalvokite kelis būdus vektorių
xišrikiuoti mažėjimo tvarka nenaudojant f-jossort()parametrodecreasing = TRUELentelės
tyrimaseilutes išrikiuokite pagal visus tris jos kintamuosius iš karto: pagalZ, tada pagalX, o esant vienodoms jų reikšmėms, pagalY.
5.2.2 Duomenų lentelių pertvarkymas
Įprastai duomenų saugojimo formatuose (txt, xlsx) duomenys surašomi taip vadinamu wide formatu: viename stulpelyje surašytos vieno kintamojo reikšmės, kintamųjų paprastai būna ne vienas, o vieną objektą aprašo viena eilutė. Toks surašymo būdas yra natūralus, tačiau ne visada patogus duomenų analizei.
Funkcija stack()
Funkcija stack() leidžia kelis vienos duomenų lentelės kintamuosius apjungti į vieną kintamąjį.
| Argumentas | Reikšmė |
|---|---|
x |
wide formato duomenų lentelė |
select |
duomenų lentelės kintamasis arba kintamųjų vektorius |
Šios funkcijos rezultatas yra lentelė, kur stulpelyje values surašomos kintamųjų reikšmės, o stulpelyje ind - tų kintamųjų pavadinimai.
Kodas
kintamieji <- read.table(header = TRUE, text = "
X Y Z
1.5 3.2 0.2
1.2 3.9 0.7
1.9 3.5 0.5
1.7 3.4 0.1
")
matavimai <- stack(kintamieji)
matavimai
#> values ind
#> 1 1.5 X
#> 2 1.2 X
#> 3 1.9 X
#> 4 1.7 X
#> 5 3.2 Y
#> 6 3.9 Y
#> 7 3.5 Y
#> 8 3.4 Y
#> 9 0.2 Z
#> 10 0.7 Z
#> 11 0.5 Z
#> 12 0.1 ZApjungimo rezultatas yra taip vadinamo long formato lentelė, kurioje į vieną kintamąjį apjungtos visų trijų lentelės kintamųjų reikšmės.
Naudojant parametrą select galima pasirinkti, kuriuos kintamuosius apjungti. Su minuso ženklu nurodyti kintamieji neapjungiami.
Funkcija unstack()
Galima ir atviršktinė duomenų lentelės transformacija su funkcija unstack(), kai apjungti stulpeliai išskaidomi į atskirus kintamuosius.
| Argumentas | Reikšmė |
|---|---|
x |
long formato duomenų lentelė |
form |
formulė, kuri nurodo, kaip į stulpelius išskaidyti kintamąjį |
Formulė yra simbolinė išraiška nusakanti ryšį tarp kintamųjų. Čia ji rašoma taip: X ~ G, kur X yra suskaidomas kintamasis, o G grupavimo kintamasis.
Jeigu long formato lentelė buvo gauta naudojant funkciją stack(), atvirkštinė transformacija atliekama nenaudojant jokių parametrų, nes jie užrašyti atributuose.
Kodas
unstack(matavimai)
#> X Y Z
#> 1 1.5 3.2 0.2
#> 2 1.2 3.9 0.7
#> 3 1.9 3.5 0.5
#> 4 1.7 3.4 0.1Jei kintamojo reikšmes grupuojančių kintamųjų yra ne vienas, galima nurodyti, pagal kurį iš jų atliekamas išskaidymas į atskirus stulpelius.
Kodas
matavimai <- read.table(header = TRUE, text = "
reiksme tipas grupe
1.5 X Pirmas
1.2 X Pirmas
1.9 X Pirmas
1.7 X Pirmas
3.2 Y Pirmas
3.9 Y Pirmas
3.5 Y Antras
3.4 Y Antras
0.2 Z Antras
0.7 Z Antras
0.5 Z Antras
0.1 Z Antras
")
unstack(matavimai, form = reiksme ~ tipas)
#> Y X Z
#> 1 3.2 1.5 0.2
#> 2 3.9 1.2 0.7
#> 3 3.5 1.9 0.5
#> 4 3.4 1.7 0.1
unstack(matavimai, form = reiksme ~ grupe)
#> Antras Pirmas
#> 1 3.5 1.5
#> 2 3.4 1.2
#> 3 0.2 1.9
#> 4 0.7 1.7
#> 5 0.5 3.2
#> 6 0.1 3.9Funkcija reshape()
Sudėtingesnės struktūros duomenų lentelių pertvarkymui naudojama funkcija reshape().
| Argumentas | Reikšmė |
|---|---|
data |
long arba wide formato duomenų lentelė |
varying |
pasikartojančius matavimus atitinkantys lentelės kintamieji |
v.names |
kintamojo vardas, į kurį apjungiami pasikartojantys matavimai |
idvar |
vienas ar keli grupavimo kintamieji |
timevar |
kintamasis, kuris long lentelėje nurodo vieną matavimų seriją |
direction |
long arba wide reikšmė, nurodo į kokį formatą tranformuoti lentelę |
Pavyzdžiui, turime lentelę kurią sudaro trys to paties kintamojo matavimai ir grupavimo kintamasis. Sudarysime lentelę, kurioje kintamieji X.1, X.2 ir X.3 apjungiami į vieną kintamąjį.
Kodas
df_wide <- read.table(header = TRUE, text = "
nr grupe X.1 X.2 X.3
1 A 2.84 2.08 1.06
2 B 2.95 2.08 0.96
3 A 2.85 2.03 1.10
4 B 3.07 1.90 0.96
5 A 3.21 1.99 1.11
6 B 2.87 1.97 0.90
")Paprasčiausiu atveju funkcijai užtenka nurodyti tik pasikartojančius matavimus atitinkančių kintamųjų vardus, kiti automatiškai priskiriami parametrui idvar.
Kodas
df_wide_to_long <- reshape(df_wide,
direction = "long",
varying = c("X.1", "X.2", "X.3")
)
df_wide_to_long
#> nr grupe time X id
#> 1.1 1 A 1 2.84 1
#> 2.1 2 B 1 2.95 2
#> 3.1 3 A 1 2.85 3
#> 4.1 4 B 1 3.07 4
#> 5.1 5 A 1 3.21 5
#> 6.1 6 B 1 2.87 6
#> 1.2 1 A 2 2.08 1
#> 2.2 2 B 2 2.08 2
#> 3.2 3 A 2 2.03 3
#> 4.2 4 B 2 1.90 4
#> 5.2 5 A 2 1.99 5
#> 6.2 6 B 2 1.97 6
#> 1.3 1 A 3 1.06 1
#> 2.3 2 B 3 0.96 2
#> 3.3 3 A 3 1.10 3
#> 4.3 4 B 3 0.96 4
#> 5.3 5 A 3 1.11 5
#> 6.3 6 B 3 0.90 6Kintamuosius parametrams galima išvardinti nurodant jų stulpelių numerius. Čia kintamajam, gautam apjungiant pasikartojančius matavimus, suteiksime vardą V.
Kodas
df_wide_to_long <- reshape(df_wide,
direction = "long",
varying = 3:5,
v.names = "V",
idvar = 1:2
)
df_wide_to_long
#> nr grupe time V
#> 1.A.1 1 A 1 2.84
#> 2.B.1 2 B 1 2.95
#> 3.A.1 3 A 1 2.85
#> 4.B.1 4 B 1 3.07
#> 5.A.1 5 A 1 3.21
#> 6.B.1 6 B 1 2.87
#> 1.A.2 1 A 2 2.08
#> 2.B.2 2 B 2 2.08
#> 3.A.2 3 A 2 2.03
#> 4.B.2 4 B 2 1.90
#> 5.A.2 5 A 2 1.99
#> 6.B.2 6 B 2 1.97
#> 1.A.3 1 A 3 1.06
#> 2.B.3 2 B 3 0.96
#> 3.A.3 3 A 3 1.10
#> 4.B.3 4 B 3 0.96
#> 5.A.3 5 A 3 1.11
#> 6.B.3 6 B 3 0.90Tokią pertvarkytą lentelę galima atstatyti atgal į pradinę panaudojant tą pačia f-ją reshape() be jokių parametrų (visų jų reikšmės surašytos lentelės atributuose).
Kodas
reshape(df_wide_to_long)
#> nr grupe X.1 X.2 X.3
#> 1.A.1 1 A 2.84 2.08 1.06
#> 2.B.1 2 B 2.95 2.08 0.96
#> 3.A.1 3 A 2.85 2.03 1.10
#> 4.B.1 4 B 3.07 1.90 0.96
#> 5.A.1 5 A 3.21 1.99 1.11
#> 6.B.1 6 B 2.87 1.97 0.90Pertvarkant lentelę iš wide formato į long formatą, funkcija reshape() visada sukuria stulpelį time, kuriame nurodomas pasikartojančio matavimo numeris.
Jei pradinė lentelė jau yra long formato ir ją reikia paversti į wide formatą, argumentui timevar būtina nurodyti tokį esamą kintamąjį iš duomenų, kuris atitiktų tą patį time kintamąjį, kokį reshape() būtų sukūrusi atliekant priešingą (iš wide į long) pertvarkymą.
Pavyzdžiui, turime pradinius long formato duomenis. Čia time kintamąjį atitinkantis stulpelis yra pavadinimu bandymas.
Kodas
df_long <- read.table(header = TRUE, text = "
nr grupe bandymas X
1 A 1 2.84
2 B 1 2.95
3 A 1 2.85
4 B 1 3.07
5 A 1 3.21
6 B 1 2.87
1 A 2 2.08
2 B 2 2.08
3 A 2 2.03
4 B 2 1.90
5 A 2 1.99
6 B 2 1.97
1 A 3 1.06
2 B 3 0.96
3 A 3 1.10
4 B 3 0.96
5 A 3 1.11
6 B 3 0.90
")Transformuojant duomenis į wide formatą, nurodomi privalomi parametrai idvar ir timevar. Taip pat parametrui v.names nurodomi pasikartojančių matavimų kintamieji - šiuo atveju vienas kintamasis X.
Kodas
df_long_to_wide <- reshape(df_long,
direction = "wide",
idvar = c("nr", "grupe"),
timevar = "bandymas",
v.names = "X"
)
df_long_to_wide
#> nr grupe X.1 X.2 X.3
#> 1 1 A 2.84 2.08 1.06
#> 2 2 B 2.95 2.08 0.96
#> 3 3 A 2.85 2.03 1.10
#> 4 4 B 3.07 1.90 0.96
#> 5 5 A 3.21 1.99 1.11
#> 6 6 B 2.87 1.97 0.90Analogiškai su wide -> long transformacijomis, taip ir long -> wide
transformacijas galima grąžinti atgal dar kartą pritaikius reshape() funkciją be jokių parametrų.
Kodas
reshape(df_long_to_wide)
#> nr grupe bandymas X
#> 1.A.1 1 A 1 2.84
#> 2.B.1 2 B 1 2.95
#> 3.A.1 3 A 1 2.85
#> 4.B.1 4 B 1 3.07
#> 5.A.1 5 A 1 3.21
#> 6.B.1 6 B 1 2.87
#> 1.A.2 1 A 2 2.08
#> 2.B.2 2 B 2 2.08
#> 3.A.2 3 A 2 2.03
#> 4.B.2 4 B 2 1.90
#> 5.A.2 5 A 2 1.99
#> 6.B.2 6 B 2 1.97
#> 1.A.3 1 A 3 1.06
#> 2.B.3 2 B 3 0.96
#> 3.A.3 3 A 3 1.10
#> 4.B.3 4 B 3 0.96
#> 5.A.3 5 A 3 1.11
#> 6.B.3 6 B 3 0.90Naudojant funkciją
unstack(), lentelętyrimaspertvarkykite iš long formato į wide. Suskaidyti reikia kintamąjįY, o jo grupavimas atliekamas pagal kintamąjįX. Kodėl tokios lentelės pervarkymui netinka funkcijareshape()?Sugalvokite būdą, kaip lentelės
df_widekintamuosiusX.1,X.2irX.3apjungti naudojant funkcijąstack().Pertvarkykite lentelę
chickwts: kintamąjįweightpadalinkite į grupes pagal kintamojofeedreikšmes.
5.3 Duomenų apjungimas
Iš duomenų struktūrų skyriaus jau žinome apie duomenų lentelių pozicinius jungimus: funkcija cbind() sudeda stulpelius šalia pagal eilučių poziciją (arba vardus), funkcija rbind() sudeda eilutes žemyn pagal stulpelių vardus. Pirmuoju atveju rezultatas gaunams, jei tik eilučių skaičius sutampa, o antruoju - reikalaujama, jog duomenų lentelių stulpeliai yra tokie patys pagal savo pavadinimą ir tipą.
Tokio jungimo pagrindinis trūkumas – niekaip neatsižvelgiama į lenteles siejančius ryšius. Skirtinga eilučių tvarką ar nevienodas eilučių skaičus neturėtų trukdyti jungimui. Dažnu atveju duomenų lentelės turi bendrus kintamuosius (raktus), pagal kuriuos reikia apjungti lenteles. Tokio jungimo rezultatas yra dviejų lentelių sankirta, kuri gaunama naudojant funkciją merge(). Funkcijos argumentai ir naudojamis priklauso nuo jungimo tipo.
| Argumentas | Reikšmė |
|---|---|
x |
pirmo lentelės vardas |
y |
antros lentelės vardas |
by |
bendras abiejų lentelių kintamasis arba jų vektorius |
all |
FALSE, nurodo, kad į rezultato lentelę įtraukiamos tik bendros eilutės |
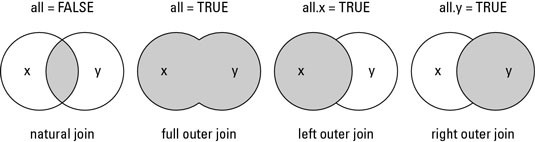
Žemiau iliustracijoje parodyti įvairūs dviejų duomenų lentelių jungimo būdai ir funkcijos merge() parametrai su atitinkamu jungimo būdu.
Turime dvi lenteles: pirmoje surašyti didžiausi Lietuvos miestai ir gyventojų skaičius juose 2001, 2011 ir 2021 metais, kitoje – miestai ir atstumas \((km)\) iki Vilniaus.
Kodas
miestai <- read.table(header = TRUE, text = "
miestas m2001 m2011 m2021
Alytus 71491 63642 52727
Jonava 34954 33172 27381
Kaunas 378650 336912 298753
Klaipėda 192954 177812 152008
Marijampolė 48675 44885 36727
Mažeikiai 42675 38819 36253
Panevėžys 119749 109028 89100
Šiauliai 133883 120969 100653
Utena 33860 31139 25343
Vilnius 542287 542932 556105
")
atstumas <- read.table(header = TRUE, text = "
miestas atstumas
Vilnius 0
Utena 96
Alytus 101
Jonava 102
Kaunas 102
Panevėžys 136
Marijampolė 138
Šiauliai 213
Mažeikiai 291
Klaipėda 311
")Abi šios lentelės turi bendrą kintamąjį miestas, pagal kurį galima apjungti jas. Jungimo kintamasis nurodomas parametrui by.
Kodas
merge(miestai, atstumas, by = 'miestas')
#> miestas m2001 m2011 m2021 atstumas
#> 1 Alytus 71491 63642 52727 101
#> 2 Jonava 34954 33172 27381 102
#> 3 Kaunas 378650 336912 298753 102
#> 4 Klaipėda 192954 177812 152008 311
#> 5 Marijampolė 48675 44885 36727 138
#> 6 Mažeikiai 42675 38819 36253 291
#> 7 Panevėžys 119749 109028 89100 136
#> 8 Šiauliai 133883 120969 100653 213
#> 9 Utena 33860 31139 25343 96
#> 10 Vilnius 542287 542932 556105 0Pagal nutylėjimą parametrui by priskiriamas abiejų lentelių bendrų kintamųjų vardų vektorius. Kadangi šiuo atveju toks kintamasis tik vienas, parametro by buvo galima ir nenurodyti.
Kodas
merge(miestai, atstumas)
#> miestas m2001 m2011 m2021 atstumas
#> 1 Alytus 71491 63642 52727 101
#> 2 Jonava 34954 33172 27381 102
#> 3 Kaunas 378650 336912 298753 102
#> 4 Klaipėda 192954 177812 152008 311
#> 5 Marijampolė 48675 44885 36727 138
#> 6 Mažeikiai 42675 38819 36253 291
#> 7 Panevėžys 119749 109028 89100 136
#> 8 Šiauliai 133883 120969 100653 213
#> 9 Utena 33860 31139 25343 96
#> 10 Vilnius 542287 542932 556105 0Gali būti, kad bendras abiejų lentelių kintamasis, pagal kurį jos apjungiamos, vienoje lentelėje įgyja vienas, o kitoje kitas reikšmes. Tokiu atveju galimi keli lentelių apjungimo būdai.
Skirtingus atvejus iliustruosime tuo pačiu miestų ir atstumų pavyzdžiu, tik iš abiejų lentelių išmesime po du įrašus tam, kad jungimo kintamojo miestas reikšmės lentelėse skirtųsi.
Kodas
miestai <- read.table(header = TRUE, text = "
miestas m2001 m2011 m2021
Jonava 34954 33172 27381
Kaunas 378650 336912 298753
Klaipėda 192954 177812 152008
Marijampolė 48675 44885 36727
Mažeikiai 42675 38819 36253
Panevėžys 119749 109028 89100
Utena 33860 31139 25343
Vilnius 542287 542932 556105
")
miestai <- dplyr::arrange(miestai, desc(miestas))
atstumas <- read.table(header = TRUE, text = "
miestas atstumas
Utena 96
Alytus 101
Kaunas 102
Panevėžys 136
Marijampolė 138
Šiauliai 213
Mažeikiai 291
Klaipėda 311
")Vidinis apjungimas
Vienas iš jungimo atvejų yra vidinis apjungimas (angl. inner join), kuris gaunamas kai atliekamas jungimas su parametro all pagal nutylėjimą naudojama reikšme lygia FALSE. Jungimo rezultatas – eilučių, pagal raktą esančių abiejose lentelėse, kintamųjų reikšmės.
Kodas
# sutrumpintai
merge(miestai, atstumas)
#> miestas m2001 m2011 m2021 atstumas
#> 1 Kaunas 378650 336912 298753 102
#> 2 Klaipėda 192954 177812 152008 311
#> 3 Marijampolė 48675 44885 36727 138
#> 4 Mažeikiai 42675 38819 36253 291
#> 5 Panevėžys 119749 109028 89100 136
#> 6 Utena 33860 31139 25343 96
# išplėstas užrašymas
merge(miestai, atstumas, by = "miestas", all = FALSE)
#> miestas m2001 m2011 m2021 atstumas
#> 1 Kaunas 378650 336912 298753 102
#> 2 Klaipėda 192954 177812 152008 311
#> 3 Marijampolė 48675 44885 36727 138
#> 4 Mažeikiai 42675 38819 36253 291
#> 5 Panevėžys 119749 109028 89100 136
#> 6 Utena 33860 31139 25343 96Šiuo atveju nors abi pradinės lentelės turėjo po 10 eilučių, po vidinio apjungimo lieka tik 6 bendros abiems lentelėms eilutės.
Pilnas apjungimas
Kai jungimo kintamojo reikšmės duomenų lentelėse skiriasi ir reikia, kad po jungimo rezultato lentelėje liktų visų rakto iš abiejų lentelių reikšmės, naudojamas pilnas apjungimas su parametru all = TRUE.
Kodas
merge(miestai, atstumas, by = "miestas", all = TRUE)
#> miestas m2001 m2011 m2021 atstumas
#> 1 Alytus NA NA NA 101
#> 2 Jonava 34954 33172 27381 NA
#> 3 Kaunas 378650 336912 298753 102
#> 4 Klaipėda 192954 177812 152008 311
#> 5 Marijampolė 48675 44885 36727 138
#> 6 Mažeikiai 42675 38819 36253 291
#> 7 Panevėžys 119749 109028 89100 136
#> 8 Šiauliai NA NA NA 213
#> 9 Utena 33860 31139 25343 96
#> 10 Vilnius 542287 542932 556105 NAKadangi lentelėje miestai jungimo kintamasis neturėjo reikšmės Alytus, tai šios rakto reikšmės stulpeliai atėję iš miestai bus lygus NA. Analogiškai, jeigu lentelėje atstumas nėra rakto reikšmės Jonava ar Vilnius, tai šių eilučių stulpeliai, atėję iš atstumas lentelės, turės NA reikšmes.
Kairysis išorinis jungimas
Nustatant parametro all.x reikšmę lygią TRUE, atliekamas kairysis išorinis jungimas. Po jungimo grąžinamos visos x lentelės eilutės, o stulpelių reikšmės iš y pridedamos tik ten, kur rakto reikšmės sutampa.
Pavyzdžiui, prie lentelės miestai prijungsime lentelės atstumas kintamuosius toms eilutėms, kurių miestas kintamojo reikšmės sutampa abiejose lentelėse.
Kodas
merge(miestai, atstumas, all.x = TRUE)
#> miestas m2001 m2011 m2021 atstumas
#> 1 Jonava 34954 33172 27381 NA
#> 2 Kaunas 378650 336912 298753 102
#> 3 Klaipėda 192954 177812 152008 311
#> 4 Marijampolė 48675 44885 36727 138
#> 5 Mažeikiai 42675 38819 36253 291
#> 6 Panevėžys 119749 109028 89100 136
#> 7 Utena 33860 31139 25343 96
#> 8 Vilnius 542287 542932 556105 NADešinysis išorinis jungimas
Tai analogiškas jungimas kairiajam išoriniam, bet su lentele y: grąžinamos visos y eilutės, o sutampančios rakto reikšmės turi ir x lentelės kintamųjų reikšmes.
Kodas
merge(miestai, atstumas, by = "miestas", all.y = TRUE)
#> miestas m2001 m2011 m2021 atstumas
#> 1 Alytus NA NA NA 101
#> 2 Kaunas 378650 336912 298753 102
#> 3 Klaipėda 192954 177812 152008 311
#> 4 Marijampolė 48675 44885 36727 138
#> 5 Mažeikiai 42675 38819 36253 291
#> 6 Panevėžys 119749 109028 89100 136
#> 7 Šiauliai NA NA NA 213
#> 8 Utena 33860 31139 25343 96Dažnos klaidos ir patarimai
Be pavyzdžių trumpai aptarsime keletą svarbių punktų taikant funkciją merge():
kai nenurodomas parametras
by, jungimas atliekamas pagal visus bendrus lentelių kintamuosius, dėl to jungimas gali būti ne toks kokio siekiama, todėl pravartu visada nurodytibyparametro reikšmę;po jungimo rezultato lentelė yra išrikiuojama pagal jungiamojo kintamojo reikšmes (mažėjimo tvarka), bet galima išlaikyti pradinį eilučių rikiavimą naudojant parametrą
sort = FALSE;jeigu jungimo kintamojo vardas apjungiamose lentelėse skiriasi, galima prieš jungimą suvienodinti vardus arba naudoti parametrus
by.xirby.yatitinkamai nurodant rakto pavadinimąxirylentelėse;jeigu abi duomenų lentelės turi kintamuosius su vienodais vardais (ir jie ne raktai), tai po jungimo prie jų vardų prirašomos priesagos (angl. suffixes)
.xpo lentelėsxkintamųjų vardų ir.ypoylentelės kintamųjų vardų (parametrassuffixes = c(".x", ".y"));jeigu rakto reikšmė turi keletą eilučių bent vienoje iš lentelių, tai tokiu atveju atliekamas vadinamas daug-su-daug (angl. many-to-many) jungimas, arba kitaip tariant, su tokia rakto reikšme jungiant bus atliekama Dekarto sandauga.
Sugalvokite būdą, kaip pradines miestų ir atstumų lenteles, kurios abi turi po 10 eilučių, apjungti nenaudojant funkcijos
merge(). Kada tokį būdą galima taikyti lentelių apjungimui?Duotos dvi lentelės:
Kodas
pastatai <- data.frame(
lokacija = 1:4,
vardas = paste0("pastatas", 1:4)
)
duomenys <- data.frame(
tyrimas = c("I", "I", "II", "II", "II"),
lokacija = c(1, 3, 2, 3, 6),
efektyvumas = c(51, 64, 70, 71, 90)
)Atlikite:
Sujunkite lenteles taip, kad rezultatas būtų sudarytas tik iš lentelės
pastataieilučių.Sujunkite lenteles taip, kad rezultatas būtų sudarytas tik iš lentelės
duomenyseilučių.Sujunkite lenteles taip, kad rezultatas būtų sudarytas tik iš bendrų jungimo kintamojo eilučių.
Sujunkite lenteles taip, kad rezultatas būtų sudarytas iš visų jungimo rakto eilučių.
- Duotos dvi lentelės:
Kodas
pastatai <- data.frame(
lokacija = 1:4,
vardas = paste0("pastatas", 1:4)
)
duomenys <- data.frame(
tyrimas = c("I", "I", "II", "II", "II"),
lokacijosID = c(1, 3, 2, 3, 6),
efektyvumas = c(51, 64, 70, 71, 90)
)Sujunkite šias dvi lenteles pagal jungimo kintamąjį lokacija ir lokacijosID taip, kad rezultate būtų visos lentelių eilutės.