R turi įvairių duomenų struktūrų. Čia pateikiami kai kurių dažniausiai naudojamų struktūrų aprašymai, tokių kaip:
3.1 Vektorius
Pagrindinis ir pats svarbiausias R duomenų formatas yra vektorius. Vektorius galima vadinti baziniu duomenų formatu, nes iš jų yra sudaromi kitos duomenų struktūros ir ne tik.
Vektorius gali būti sudarytas tik iš to paties tipo reikšmių (elementų). Pagrindiniai tipai yra:
numeric – realieji skaičiai,
double – taip pat realieji skaičia, nesiskiriantys nuo numeric,
integer – sveikieji skaičiai, rašomi kartu su raide L, pvz. 2L,
character – kabutėse rašomi simboliai,
complex – kompleksiniai skaičiai, užrašomi \(a + b\,i\) forma,
logical – loginės reikšmės (
TRUE/FALSE).
Vektorius galima sukurti įvairiais būdais. Paprastai galima naudoti funkciją vector(), kuri priima šiuos argumentus:
mode – vektoriaus elementų tipas,
length – vektoriaus elementų skaičius.
Priklausomai nuo nurodomo tipo, vektorius užpildomas tam tikromis vienodomis reikšmėmis:
Norint sukurti konkretaus tipo vektorių, galima naudoti funkcijas, kurių pavadinimai atspindi konkretų tipą. Šioms funkcijoms reikalingas vienas parametras - vektoriaus ilgis.
Reikia pabrėžti, kad R neturi atskirų skalarių reikšmių – visa, kas yra kuriama, yra vektoriai. Tai reiškia, kad kai įvedus skaičių 5, jis iš esmės yra vektorius su vienu elementu.
R turi keletą integruotų konstantų, t.y. vektorių, kurie yra įrašyti į kiekvieną R sesiją kartu su base paketu.
LETTERS
letters
month.abb
month.name
pi3.1.1 Objekto priskyrimas
Praėjusiuose pavyzdžiuose vektoriai buvo sukurti, tačiau neišsaugoti. Norint išsaugoti sukurtą objektą darbinėje sesijoje, reikia jį priskirti kintamajam:
Kodas
# "<-" priskyrimo operatorius
a <- numeric(3)
a
#> [1] 0 0 0Yra ir kitų priskyrimo operatorių, pvz. =, <<- arba -> tačiau jie dažniausiai naudojami kitose situacijose, todėl rekomenduojama visada naudoti simbolį <- kaip priskyrimo operatorių.
Sukurtą objektą galima priskirti ne tik raidėms, bet ir kitiems simboliams, žodžiams ar tekstui. Norint sukurtą objektą priskirti keliems atskirtiems žodžiams, galima naudoti tiek tašką ., tiek apatinį brūkšnelį _.
Dažnai turint jau tam tikro tipo reikšmes, jas reikia priskirti vienam objektui. Tokiu atveju naudojama funkcija c() (nuo žodžio concatinate).
Kodas
skaiciai <- c(1, 2.8, .2, 1/3, pi)
skaiciai
#> [1] 1.0000000 2.8000000 0.2000000 0.3333333 3.14159273.1.2 Vektorių atributai
Vektoriaus tipas ir ilgis - pagrindiniai iš vektorių nusakančių atributų (tačiau ne vieninteliai). Kiekvienas R objektas turi tam tikrus atributus.
Norint patikrinti koks yra vektoriaus ilgis naudojama funkcija length()
Kodas
length(char_vektorius)
#> [1] 2Vektoriaus tipą galima patikrinti su funkcijomis mode() arba typeof()
3.1.3 NA, NULL, ir kitos konstantos
Kaip ir kitos progamavimo kalbos, R turi specifinį žymėjimą išskirtinėm reikšmėm:
– NA - praleista reikšmė (not available),
– NaN - neapibrėžtumas (Not a Number),
– Inf - begalybė, numeric tipo reikšmė,
– NULL - specialus tuščias objektas.
Statistiniuose duomenų rinkiniuose dažnai susiduriama su trūkstamais duomenimis, kurie R kalboje žymimi reikšme NA. Tuo tarpu NULL nurodo, kad atitinkama reikšmė tiesiog neegzistuoja, o ne tai, kad ji egzistuoja, bet yra nežinoma.
Norint patikrinti, kurie vektoriaus elementai turi bent vieną iš išvardintų specialių reikšmių, naudojamos is._reiksme_() tipo funkcijos.
| 0 | Inf | NA | NaN | |
|---|---|---|---|---|
is.finite() |
x | |||
is.infinite() |
x | |||
is.na() |
x | x | ||
is.nan() |
x |
Kokio tipo objektą grąžina funkcija is.na()?
Apskaičiuokite, kokio ilgio yra vektorius
LETTERS.Patikinkite, ar jo ilgis sutampa su vektoriaus
lettersilgiu.Sukurkite vektorių sudarytą tik iš
NAirNaNreikšmių. Patikrinkite vektoriaus tipą.
3.1.4 Vektoriaus elementų vardai ir atributai
Vektoriaus elementai gali turėti vardus. Vardų priskyrimą galima atlikti keliais būdais. Pavyzdžiui, suteikiami elementams vardai vektoriaus sukūrimo metu.
Kodas
vektorius_su_vardais <- c("pirmadienis" = 25, "antradienis" = 27, 'trečiadienis' = 24.5)Vektoriaus vardus galima patikrinti su funkcija names().
Kodas
names(vektorius_su_vardais)
#> [1] "pirmadienis" "antradienis" "trečiadienis"Kokio tipo objektą grąžina funkcija names()? Nuo ko priklauso šios funkcijos grąžinamo objekto ilgis?
Funkcija names() naudojama pakeisti arba sukurti naują vardų vektorių. Tarkime, kad turime vektorių, kurio elementai neturi vardų (t.y. vardų vektorius yra tuščias). Tokiu atveju, iškvietus names(skaiciai), grąžinama reikšmė NULL.
Kodas
names(skaiciai)
#> NULLVardų vektoriui priskiriamas naujas vektorius, kuriame surašyti elementų vardai.
Dabar vektorius skaiciai pasipildė nauju atributu - elementų vardais. Norint patikrinti vektoriaus keičiamus atributus, naudojama funkcija attributes().
Kodas
attributes(skaiciai)
#> $names
#> [1] "vardas1" "vardas2" "vardas3" NA NAVektoriaus vardai yra jo atributas, todėl juos galima keisti naudojant funkciją attr().
Apie atributus galima galvoti kaip apie papildomą informaciją apie patį objektą. Metainformacija reikalinga dokumentuojant turinį. Pavyzdžiui, galbūt reikalinga vektoriaus versija ir sukūrimo data.
Kodas
attr(skaiciai, "versija") <- "0.1"
attr(skaiciai, "sukurimo_data") <- "2025-09-17"
attributes(skaiciai)
#> $names
#> [1] "I" "II" "III" NA NA
#>
#> $versija
#> [1] "0.1"
#>
#> $sukurimo_data
#> [1] "2025-09-17"Sukurkite loginį vektorių iš 4 elementų ir priskirkite jiems vardus pagal šabloną: asmuo_X, kur X - elemento pozicija.
Priskirkite vektoriui naują atributą, pavadintą apie, kuriame būtų išsaugotas sakinys: indikatorinis požymio vektorius.
Kodas
# 1.
vektorius <- c(TRUE, FALSE, FALSE, TRUE)
names(vektorius) <- paste0("asmuo_", 1:4)
vektorius
#> asmuo_1 asmuo_2 asmuo_3 asmuo_4
#> TRUE FALSE FALSE TRUE
# 2.
attr(vektorius, "apie") <- "indikatorinis požymio vektorius"
attributes(vektorius)
#> $names
#> [1] "asmuo_1" "asmuo_2" "asmuo_3" "asmuo_4"
#>
#> $apie
#> [1] "indikatorinis požymio vektorius"3.1.5 Vektoriaus indeksavimas
Viena iš svarbiausių ir dažniausiai naudojamų R operacijų yra vektorių indeksavimas. Operacijos metu pasirenkama dalis vektoriaus elementų pagal tam tikrus indeksus.
Pasirinkti elementus naudojami laužtiniai skliaustai []. Pavyzdžiui, pasirenkamas pirmasis vektoriaus x elementas.
Kodas
skaiciai[1]
#> I
#> 1Kitaip nei kitose programavimo kalbose, R pirmasis indeksas prasideda nuo 1, o ne nuo 0. Taigi, skaiciai[0] grąžintų klaidą.
Jeigu reikia pasirinkti daugiau nei vieną elementą, tada nurodomas indeksų vektorius.
Pasirenkamų elementų tvarka nėra svarbi. Taip pat galima pasirinkti tuos pačius elementus ne vieną kartą.
Kodas
i <- c(4, 4, 1, 1)
skaiciai[i]
#> <NA> <NA> I I
#> 0.3333333 0.3333333 1.0000000 1.0000000Jeigu norime nepasirinkti tam tikro elemento, užtenka nurodyti prie indeksų minuso ženklą.
Kodas
skaiciai[-1]
#> II III <NA> <NA>
#> 2.8000000 0.2000000 0.3333333 3.1415927
skaiciai[-c(1, 3)]
#> II <NA> <NA>
#> 2.8000000 0.3333333 3.1415927Jei vektoriaus elementai turi vardus, tai konkrečius elementus galima pasirinkti nurodant jų vardus.
Kodas
vektorius[c("asmuo_3", "asmuo_4")]
#> asmuo_3 asmuo_4
#> FALSE TRUEElemento poziciją galima nurodyti ne tik indeksu, bet ir loginėmis reikšmėmis. Apie tai plačiau skyrelyje 3.1.7.
Pasirinkus konkretų vektoriaus elementą, jo reikšmę galima pakeisti. Tai padaryti labai paprasta – pakanka pasirinktam indeksui priskirti naują reikšmę.
Kodas
skaiciai[1] <- log(10)Jei nurodomas indeksas, kuris viršija esamą vektoriaus ilgį, R automatiškai praplečia vektorių: naujame indekse įrašo priskirtą reikšmę, o tarp praleistų pozicijų įterpia NA.
Sukurkite vektorių su 5 elementais. Tarkime, jog vektoriaus ilgis yra nežinomas. Užrašykite komandą, kuri grąžintu paskutinį vektoriaus elementą.
Užrašykite komandą, kuri grąžintų priešpaskutinį vektoriaus elementą.
3.1.6 Skaitiniai vektoriai
Veiksmai su vektoriais
R kalba pasižymi tuo, kad joje veiksmai yra vektorizuoti. Tai reiškia, kad operacijos yra atliekamos paelemenčiui.
Veiksmai su vektoriais dažniausiai turi tenkinti vieną sąlygą - vektoriai turi būti vienodo ilgio. Kai atliekamos operacijos su vektoriais, kurie turi skirtingus ilgius, R naudoja ciklinio pratęsimo (angl. recycling) principą. Jei operacijoje dalyvauja ilgesnis ir trumpesnis vektorius, trumpesnis vektorius cikliškai pakartojamas tol, kol pasiekia ilgesnio vektoriaus ilgį.
Šią savybę galima išnaudoti, jeigu, pavyzdžiui, su visais vektoriaus elementais reikia atlikti tą patį veiksmą.
Kodas
b + 1.5
#> [1] 11.5 21.5Skaitinių vektorių generavimas
Tarkime, kad mums reikalingas visų natūrinių skaičių nuo 1 iki 10 vektorius.
Kodas
s <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s
#> [1] 1 2 3 4 5 6 7 8 9 10Aritmetinių vektorių progresijas su žingsniu 1 arba -1 galima užrašyti kompaktiškai. Tam naudojamas dvitaškio operatorius :.
Kodas
1:10 # žingsnis lygus 1
#> [1] 1 2 3 4 5 6 7 8 9 10
-10:1 # žingsnis lygus 1
#> [1] -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1
10:1 # žingsnis lygus -1 (mažėjanti skaičių seka)
#> [1] 10 9 8 7 6 5 4 3 2 1Funkcija seq()
Bendra funkcija, skaičių sekai kurti yra sequence() arba seq() trumpiau. Jos parametrai:
-
from– pirmojo generuojamos sekos nario reikšmė, -
to– paskutinio generuojamos sekos nario reikšmė, -
by– generuojamos sekos žingsnis, -
length.out– visos sekos elementų skaičius, -
along.with– vektorius, kurio elementų skaičius bus sekos ilgis.
Kodas
seq(from = 1, to = 10, by = 1)
#> [1] 1 2 3 4 5 6 7 8 9 10Kodas
seq(from = 1, to = 10, length.out = 50)
#> [1] 1.000000 1.183673 1.367347 1.551020 1.734694 1.918367 2.102041
#> [8] 2.285714 2.469388 2.653061 2.836735 3.020408 3.204082 3.387755
#> [15] 3.571429 3.755102 3.938776 4.122449 4.306122 4.489796 4.673469
#> [22] 4.857143 5.040816 5.224490 5.408163 5.591837 5.775510 5.959184
#> [29] 6.142857 6.326531 6.510204 6.693878 6.877551 7.061224 7.244898
#> [36] 7.428571 7.612245 7.795918 7.979592 8.163265 8.346939 8.530612
#> [43] 8.714286 8.897959 9.081633 9.265306 9.448980 9.632653 9.816327
#> [50] 10.000000Kodas
seq(from = 1, to = 10, along.with = x)
#> [1] 1 4 7 10Naudojant arba tik argumentą length.out arba tik argumentą along.with, galima naudoti šias komandas atitinkančias trumpesnes funkcijas.
Kodas
# 1.
seq(1, 100, 2)
#> [1] 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
#> [26] 51 53 55 57 59 61 63 65 67 69 71 73 75 77 79 81 83 85 87 89 91 93 95 97 99
# 2.
seq(0, 1, by=0.1)
#> [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
# 3.
0:10 / 10
#> [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0Funkcija rep()
Pasikartojančių elementų turinčios sekos generavimui naudojama funkcija rep(). Jos parametrai:
- x – vektorius, kurį reikia pakartoti,
- times – viso vektoriaus pakartojimų skaičius,
- length.out – bendras sekos elementų skaičius,
- each – vektoriaus elementų pakartojimų skaičius.
Funkcijos veikimo pavyzdžius patikrinsime su vektoriumi v.
Kodas
v <- 1:3
v
#> [1] 1 2 3Viso vektoriaus pakartojimų skaičių nurodo parametras times. Tokiu atveju prie vektoriaus galo prijungiamas toks pat vektorius ir tai pakartojama times kartų.
Kodas
rep(v, times = 3)
#> [1] 1 2 3 1 2 3 1 2 3Vektoriaus elementų pakartojimų skaičius gali būti individualus. Tokiu atveju parametro times reikšmė bus tokio pat ilgio vektorius su pakartojimų reikšmėmis.
Tuo atveju, jei visi vektoriaus elementai turi būti pakartoti vienodą skaičių kartų, paprasčiau tą skaičių nurodyti parametrui each – komanda bus aiškesnė.
Sugeneruotos sekos ilgis nebūtinai turi būti vektoriaus x ilgio kartotinis, jos ilgį galima apriboti per parametrą length.out. Pvz., vektorių v kartojame, kol visos sekos ilgis bus lygus 10.
Kodas
rep(v, length.out = 10)
#> [1] 1 2 3 1 2 3 1 2 3 1Galima nurodyti iš karto kelis argumentus, tačiau svarbu žinoti, kad parametras each turi didesnį prioritetą prieš parametrą times.
Kodas
rep(v, each = 2, times = 2)
#> [1] 1 1 2 2 3 3 1 1 2 2 3 3Pakartojamas vektorius gali būti bet kokio tipo. Jis gali turėti ir vieną reikšmę.
Kodas
rep("tekstas", times = 3)
#> [1] "tekstas" "tekstas" "tekstas"Užrašykite
rep()komandą, kuri iš vektoriaus 0:1 sudarytų seką 0, 1, 0, 1, 0, 1.Užrašykite
rep()komandą, kuri iš vektoriaus 0:1 sudarytų seką 0, 0, 0, 1, 1, 1.Komandos
rep(2, 4)rezultatą gaukite panaudodami funkcijąseq().Užrašykite
rep()komandą, kuri iš vektoriausvsudarytų seką 1, 2, 2, 3, 3, 3
3.1.7 Loginiai vektoriai
Kitas vektorių tipas - loginiai vektoriai, galintis turėti logines reikšmes TRUE, FALSE arba NA.
Loginius vektorius galima gauti įvairiais būdais:
- tiesiogiai sukuriant
Kodas
loginis.v1 <- c(TRUE, FALSE, FALSE, TRUE) - naudojant palyginimo operatorius:
==, !=, >, <, >=, <=
Kodas
x >= 3
#> [1] FALSE FALSE FALSE TRUE- kaip tam tikrų funkcijų rezultatą
Konstantas TRUE ir FALSE galima rašyti sutrumpinta forma, atitinkamai T ir F.
Turint loginį vektorių, galima išrinkti tam tikrus vektoriaus elementus, nustatyti reikiamų elementų eilės numerius, patikrinti logines sąlygas.
Pagrindiniai loginiai operatoriai yra šie:
– | - loginis ARBA,
– & - loginis IR,
– ! - loginis NE.
Kai loginių operatorių argumentai (operandai) yra vektoriai, tai loginės operacijos atliekamos su tų vektorių elementais.
Kodas
a | b
#> [1] TRUE TRUE TRUE FALSE
a & b
#> [1] FALSE FALSE FALSE FALSE
!a
#> [1] FALSE FALSE TRUE TRUEOperatoriai ARBA ir IR turi ilgąją formą, || ir &&. Nuo trumposios ji skiriasi tuo, kad loginė operacija atliekama tik su pirmąja loginio vektoriaus reikšme. Šiuos operatorius galima naudoti tokiose situacijose, kur reikia, kad loginės operacijos rezultatas būtų viena reikšmė: arba TRUE, arba FALSE.
Loginius operatoriai naudojami apjungti logines sąlygas. Pavyzdžiui, tikrinama ar vektoriaus x elementų reikšmės patenką į intervalą \([1, 4]\).
Kodas
x >= 1 & x <= 4
#> [1] TRUE FALSE TRUE FALSENorint patikrinti, ar bent viena loginio vektoriaus elemento reikšmė yra TRUE, naudojama funkcija any().
Kodas
any(a)
#> [1] TRUENorint patikrinti, ar visi loginio vektoriaus elementai lygūs TRUE, naudojama funkcija all().
Kodas
all(a)
#> [1] FALSELoginį vektorių galima sudaryti ir funkcijos viduje, argumento pozicijoje.
Kodas
all(x > 0)
#> [1] FALSEKonstantos FALSE ir TRUE atitinka skaičius 0 ir 1, todėl loginius vektorius galima sumuoti. Tokiu būdu surandame TRUE reikšmę turinčių elementų kiekį. Pavyzdžiui, apskaičiuosime, kiek yra vektoriaus x elementų, didesnių už atitinkamus vektoriaus y elementus.
Kodas
sum(x > y)
#> [1] 3- Duoti kelių dienų oro temperatūrų matavimai: 18, 22, 15, 27, 30, 19, 21. Sudarykite loginus vektorius
karsta, kurTRUEnurodo, kad temperatūra viršijo 25°C,-
vidutiniska, kurTRUEnurodo, kad temperatūra yra tarp 18°C ir 25°C (įskaitant).Suskaičiuokite, kiek buvo dienų, kai temperatūra nei karšta nei vidutiniška.
Užrašykite komandą, kuri patikrintų, ar visų loginio vektoriaus
aelementų reikšmės yra FALSE.Užrašykite komandą, kuri patikrintų, ar bent vienas vektoriaus
xelementas nelygus nuliui.(*) Patikrinkite, ar visi vektoriaus
xelementai priklauso vektoriausyelementų aibei. Komandą galima užrašyti su f-jais.element().
Filtravimas naudojant logines reikšmes
Vektoriaus elementus galima išrinkti sudarius to paties ilgio loginių reikšmių vektorių, kur TRUE reiškia, jog reikšmė reikia išrinkti, o FALSE – neišrinkti. Pavyzdžiui, iš vektoriaus x išrinksime pirmą ir trečią narius.
Kodas
i <- c(TRUE, FALSE, TRUE, FALSE)
x[i]
#> [1] 2 2Toks indeksų vektorius labai dažnai gaunamas tikrinant kokią nors sąlygą. Pavyzdžiui, iš vektoriaus x išskirsim tuos elementus, kurių reikšmė didesnė už 1.
Kodas
i <- x > 1
x[i]
#> [1] 2 2 5Vektoriaus elementų išrinkimą, tikrinant loginį sąlygą, galima užrašyti kompaktiškiau.
Kodas
x[x > 1]
#> [1] 2 2 5Jei veiksmų su vektoriais rezultatas yra vektorius, iš kurio reikia dar kartą išrinkti tam tikrą elementà, tokį veiksmą galima padaryti dar kartą naudojant išrinkimo operatorių [ ir nesukuriant tarpinio vektoriaus. Pvz., iš vektoriaus x išrinksime trečiajį elementą, kurio reikšmė didesnė už 1.
Kodas
x[x > 1][3]
#> [1] 5Specialios loginės funkcijos
R turi keletą specialių funkcijų, kurios skirtos tam tikroms įvairių objektų savybėms patikrinti.
Kartais reikia patikrinti, ar egzistuoja konkretus kintamasis arba funkcija. Tam naudojama funkcija exists(). Ieškomo objekto vardas rašomas kabutėse. Kitas parametras mode nurodo ieškomo objekto tipą. Pagal nutylėjimą mode = "any", todėl ieškomi bet kokie tokį vardą turintys objektai.
Skyrelyje 3.1.3 paminėtos is.__() tipo funkcijos, skirtos patikrinti ar objektas turi tam tikro tipo konstantą. Tokių funkcijų, kurios būtų skirtos patikrinimui, yra ir daugiau.
Pavyzdžiui, funkcijos is.numeric(), is.character(), is.logical() yra skirtos patikrinti vektoriaus elementų tipą su pasirinktu tipu.
Taip pat galima patikrinti ar objektas yra tam tikros duomenų struktūros klasės is.vector(), is.matrix(), is.list(), is.data.frame().
3.1.8 Kategoriniai vektoriai
Daugelis R operacijų, ypač taikomų lenteliniams duomenims, remiasi faktoriais. Programavimo kalboje R faktoriais vadinami vardų (nominaliosios) arba rangų (ordinaliosios) skalės kintamieji, kurie gali įgyti tik baigtinį skaičių skirtingų reikšmių. Statistikoje tokie kintamieji dar vadinami kategoriniais.
Vardų (nominalieji) kintamieji neturi natūralios tvarkos. Pavyzdžiui, politinė priklausomybė gali būti „Demokratas“, „Respublikonas“, „Nepriklausomas“. Šių kategorijų rikiuoti „nuo mažiausios iki didžiausios“ nėra prasmės.
Ranginiai (ordinalieji) turi prasmingą eiliškumą. Pavyzdžiui, pasitenkinimo lygiai „žemas < vidutinis < aukštas“ arba išsilavinimas „bakalauras < magistras < daktaras“. Čia reikšmių (lygių) rikiavimas didėjimo tvarka atspindi realų rangą.
Kategorinių kintamųjų reikšmės dažnai būna užkoduotos žodžiais, trumpiniais, simboliais arba skaičiais, tačiau pačios reikšmės nėra skaitinės - jos žymi atskiras kategorijas.
Sukurti kategorinį, arba R kalboje vadinama faktorių, kintamąjį naudojama funkcija factor(). Pagrindiniai funkcijos argumentai:
| Argumentas | Paskirtis |
|---|---|
x |
Kategorinio kintamojo reikšmių vektorius. |
levels |
Visų galimų reikšmių vektorius (jei nurodoma iš anksto). |
labels |
Kintamojo reikšmių pavadinimų vektorius. |
ordered |
TRUE, jei kintamasis yra ranginis. |
Išnagrinėkime faktorių, sudarytą iš skaitinių kodų.
Galima patikrinti, kas sudaro šį objektą su funkcija str().
Kodas
str(xf)
#> Factor w/ 3 levels "5","12","13": 1 3 2 3Išvestyje matome, kad faktorius sudarytas iš trijų kategorijų, tačiau patys duomenys faktoriuje yra ne kategorijų reikšmės, o lygių indeksai - 1, 3, 2, 3. Tai nurodo, kad pirmas elementas yra 1-ojo lygio, antras yra 3-iojo lygio ir t.t. Kitaip tariant faktoriaus duomenys yra natūraliųjų skaičių vektorius. Patikrinus faktoriaus reikšmių tipą - gaunamas teiginio patvirtinimas.
Kodas
mode(xf)
#> [1] "numeric"Faktoriaus ilgis visada lygus pačių elementų skaičiui – ne lygių kiekiui.
Kodas
length(xf)
#> [1] 4Kuriant faktorių kategorijas galima apibrėžti su argumentu levels. Naudinga, kai iš anksto yra žinomos visos galimos kategorijos, nors ne visos kategorijų reikšmės pasirodo pačiame vektoriuje.
Apibrėžus galimas kategorijas, vėliau šias reikšmes galima įtraukti į faktorių.
Kodas
xf[2] <- 88
xf
#> [1] 5 88 12 13
#> Levels: 5 12 13 88Tačiau bandant įtraukti kategoriją, kuri nėra nurodyta, gaunamas įspėjamasis pranešimas, kad reikšmė konvertuota į NA. Tai įvyksta todėl, nes faktorius neatpažįsta kategorijos, kuri nėra apibrėžta tarp levels reikšmių.
Kodas
xf[2] <- 25
xf
#> [1] 5 <NA> 12 13
#> Levels: 5 12 13 88Kokias skirtingas reikšmes turi kategorinis kintamasis, parodo funkcija levels(), o kategorijų kiekį - funkcija nlevels().
Jeigu norima sukurti ranginį kintamąjį, reikia naudoti argumentą ordered=TRUE. Svarbu žinoti, kad funkcijoje reikia nurodyti kategorijas pagal jų rangus (mažiausias - didžiausias). Nenurodžius, kategorijos ir jų rangai surašomi pagal abėcėlę.
Kadangi ordered=TRUE, kategorijos turi rikiavimo prasmę, taigi galima palyginti.
Kodas
šv_f[1] < šv_f[4]
#> [1] TRUEFunkcija is.ordered() nurodo, ar faktorius yra ranginis kintamasis.
Kodas
is.ordered(šv_f)
#> [1] TRUEFaktorių sekos generavimas
Faktoriaus kategorijų seką galima sugeneruoti su funkcija gl().
| Argumentas | Paskirtis |
|---|---|
n |
Skirtingų kategorijų skaičius. |
k |
Reikšmių paeiliui pakartojimų skaičius. |
length |
Bendras sugeneruotos sekos ilgis. |
labels |
Faktoriaus įgyjamų reikšmių pavadinimų vektorius |
ordered |
TRUE, jei kintamasis yra ranginis. |
Dvi kategorijos, kiekviena pakartota po penkis kartus. Kadangi vardų vektorius nenurodytas, tai kategorijas atstoja numeriai 1 ir 2.
Kodas
gl(n = 2, k = 5)
#> [1] 1 1 1 1 1 2 2 2 2 2
#> Levels: 1 2Sekos bendras ilgis 10 reikšmių sudarytų iš dviejų kategorijų, kurios paeiliui pakartotos po vieną kartą. Kategorijoms uždėtos žymos.
Sugeneruoti faktorių
h, kuris turėtų po 5 kartus pasikartojančias tris kategorijas, ir suteikite joms vardus “I lygis”, “II lygis” ir “III lygis”.Faktorių
hsu tokiais pat kategorijų pavadinimai sudarykite naudodami funkcijasrep()irfactor().Sugeneruokite faktorių
d, kuris reikštų visas vieno mėnesio savaitės dienas. Tarkime, kad mėnuo turi 30 dienų, o savaitės dienas pradedame skaičiuoti nuo pirmadienio. Savaitės dienoms suteikite pilnus vardus.
Kodas
# 1.
h <- gl(n = 3, k = 5, labels = c("I lygis", "II lygis", "III lygis"))
h
#> [1] I lygis I lygis I lygis I lygis I lygis II lygis II lygis
#> [8] II lygis II lygis II lygis III lygis III lygis III lygis III lygis
#> [15] III lygis
#> Levels: I lygis II lygis III lygis
# 2.
h <- rep(x = 1:3, each = 5)
h <- factor(h, labels = c("I lygis", "II lygis", "III lygis"))
h
#> [1] I lygis I lygis I lygis I lygis I lygis II lygis II lygis
#> [8] II lygis II lygis II lygis III lygis III lygis III lygis III lygis
#> [15] III lygis
#> Levels: I lygis II lygis III lygis
# 3.
dienos <- c("Pirma", "Antra", "Trečia", "Ketvirta", "Penkta", "Šešta", "Sekma")
dienos <- paste0(dienos, "dienis")
d <- gl(n = 7, k = 1, length = 30, labels = dienos)
d
#> [1] Pirmadienis Antradienis Trečiadienis Ketvirtadienis Penktadienis
#> [6] Šeštadienis Sekmadienis Pirmadienis Antradienis Trečiadienis
#> [11] Ketvirtadienis Penktadienis Šeštadienis Sekmadienis Pirmadienis
#> [16] Antradienis Trečiadienis Ketvirtadienis Penktadienis Šeštadienis
#> [21] Sekmadienis Pirmadienis Antradienis Trečiadienis Ketvirtadienis
#> [26] Penktadienis Šeštadienis Sekmadienis Pirmadienis Antradienis
#> 7 Levels: Pirmadienis Antradienis Trečiadienis Ketvirtadienis ... SekmadienisFaktorių reikšmių keitimas
Nesvarbu, ar sukurtas faktorius yra vardų ar ranginis, nenurodžius kategorijų reikšmių argumento levels, kategorijos yra išdėstomos abėcėlės tvarka. Pavyzdžiui, sukūrus vardinį vektorių sudaryta iš dviejų kategorijų “Vyras” ir “Moteris”, galima įsitikinti, jog kategorijų reikšmės yra išvedamos pagal abėcėlę.
Tuo atveju, kai reikia nustatyti arba pakeisti jau sudaryto faktoriaus bazinę (reference) reikšmę, naudojama funkcija relevel(). Čia nustatoma “Vyras” kaip bazinė reikšmė.
Kodas
f <- relevel(f, ref = "Vyras")Dažnai pasitaiko, jog kategorinio kintamojo reikšmės yra koduojamos skaičiais. Pavyzdžiui, prilyginus “Vyras” reikšmę 0, o “Moteris” - 1, tą patį vektorių x galima užrašyti taip: \((0, 1, 1, 0)\). Sudarant faktorių, tų kodų reikšmes galima atstatyti užrašant pavadinimų vektorių labels.
Tarkime, kad duotas vektorius
c(1, -1, 0, -1, -1, 1, -1, 0, 1, 1, -1, 0, 1, 1, 0). Čia reikšmės reiškia atsakymus į testo klausimus. Sudarykite faktoriųatsir jo reikšmėms priskirkite pavadinimus: 1 - Taip, -1 - Ne, 0 - Nežinau.Naudodami funkciją
levels(), pakeiskite prieš tai buvusiame užduočių bloke sudaryto faktoriaushkategorijų vardus į “P”, “A”, “T”.Naudodami funkciją
rev(), pakeiskite jau sudaryto faktoriaushįgyjamų kategorijų tvarką į priešingą: “T”, “A”, “P”.
3.2 Matrica
“No one can be told what the Matrix is. You have to see it for yourself.”
— Morpheus, The Matrix (1999)
Kaip minėta vektorių skyriaus pradžioje, vektorius R kalboje yra pamatinis objektas, nes iš jo sudaromi kitos duomenų struktūras. Pavyzdžiui, nuosekliai sekantis duomenų struktūrų tipas yra matrica. Tai yra vektorius su dviem papildomais atributais - eilučių ir stulpelių skaičiumi. Iš to seka, kad matricos gali būti skirtingų tipų (skaitinės, loginės, simbolių).
Iš tikrųjų matrica R kalboje yra dvimatis masyvas (array), kurio visos reikšmės yra vienodo tipo. Masyvas yra bendresnio tipo daugiamatis objektas. Pavyzdžiui, trimatis masyvas būtu sudarytas iš eilučių, stulpelių ir sluoksnių. Šiame skyriuje aptarsime tik atskirą atvejį - dvimačių masyvų objektą.
Matricos sudarymui naudojama funkcija matrix().
| Argumentas | Paskirtis |
|---|---|
data |
Vektorius, kurio reikšmėmis užpildoma matrica. |
nrow |
Matricos eilučių skaičius. |
ncol |
Matricos stulpelių skaičius. |
byrow |
loginė reikšmė, pagal nutylėjimą FALSE, matrica užpildoma stulpeliais. |
dimnames |
eilučių ir stulpelių vardų sąrašas. |
Matricos sūkurimas
Pavyzdžiui, sukursime \(5 \times 2\) matricą.
Jei nurodomas tik nrow arba tik ncol argumentas - kita dimensija apskaičiuojama iš bendro elementų skaičiaus.
Jeigu data argumentas turi mažiau reikšmių negu reikia, tai cikliškai kartojamos reikšmės tol, kol matrica užpildoma. Toki būdu lengva gauti, tarkime, nuliais užpildytą matricą.
Kodas
nuliai <- matrix(0, ncol = 2, nrow = 5)Matricos taip pat turi tipus, kurie priklauso nuo vektoriaus, kurio reikšmėmis užpildoma matrica, tipą.
Kodas
menesiai.matrica <- matrix(month.name, ncol = 3, byrow = TRUE)Jeigu matrica laikome vektoriumi, tai ji turi ir atributus ir ilgį. Standartiškai, sukurtos matricos turi iš pradžių tik vieną atributą - dimensijas.
Kodas
attributes(m)
#> $dim
#> [1] 5 2Matricos matavimą galima sužinoti su funkcija dim(), o matricos ilgis yra duomenų vektoriaus ilgis.
Jeigu norime sužinoti vieną iš matavimų, t.y. tik eilučių arba tik stulpelių skaičių, atitinkamai naudojamos funkcijos nrow() ir ncol().
Jei pašalintume matricos dimensijų atributą, tai duomenų struktūra taptu vektoriumi. Jei pridėtume prie vektoriaus dimensijų atributą - gautume matricą.
Užrašykite, kiek įmanomą trumpesnę komandą, kuri sudarytų matricą iš 10 eilučių ir 2 stulpelių, kur visi pirmo stulpelio nariai lygus 1, o antrojo lygus 2.
Sukurkite antros eilės kvadratinę matricą sudarytą iš praleistų reikšmių.
Sukurkite, trečios eilės vienetinę matricą. Naudokite funkciją
diag().
Dimensijų vardai
Matricos eilučių ir stulpelių pavadinimams nustatyti ar pakeisti naudojamos funkcijos rownames() ir colnames().
Funkcija dimnames naudojama iš karto abiejų dimensijų vardams parodyti ar jiems pakeisti. Šios funkcijos rezultatas yra sąrašas, kurio pirmas elementas yra eilučių vardo vektorius, o antras – stulpelių vardų vektorius.
Kodas
dimnames(m)
#> [[1]]
#> [1] "a" "b" "c" "d" "e"
#>
#> [[2]]
#> [1] "X" "Y"Matricos elementų išrinkimas
Analogiškai kaip ir vektoriaus elementus, matricus reikšmės galima pasiekti naudojant laužtinius skliaustus []. Kadangi matricą yra dvimatis objektas, tai galima nurodyti eilutės ir stulpelių indeksus, atskirtus kableliu.
Kodas
# pirmos eilutės ir pirmo stulpelio elementas
m[1, 1]
#> [1] 1Kaip ir vektoriams, galima nurodyti matricos eilučių ir stulpelių indeksų aibę.
Jeigu reikia išskirti tik eilutę, tai stulpelių skaičius nenurodomas.
Kodas
# išskiriama pirmoji eilutė
m[1, ]
#> X Y
#> 1 6
# išskiriamos pirmos dvi eilutės
m[1:2, ]
#> X Y
#> a 1 6
#> b 2 7Tą patį galima padaryti ir su stulpeliais.
Kodas
# išskiriamas antrasis stulpelis
m[, 2]
#> a b c d e
#> 6 7 8 9 10Jei matricos eilutės arba stulpeliai turi vardus, juos galima panaudoti nurodant konkrečias eilutes arba stulpelius.
Kodas
m[, "Y"]
#> a b c d e
#> 6 7 8 9 10Matricos eilutes ir stulpelius taip pat galima pasirinkti naudojant logines reikšmes. Pavyzdžiui, pasirinksime iš matricos m eilutes, kuriose pirmo stulpelio reikšmė didesnė nei 3.
Kodas
m[m[, 1] > 3, ]
#> X Y
#> d 4 9
#> e 5 10Užrašykite komandą, kuri matricos
mstulpelius sukeistų vietomis.Užrašykite komandą, kuri išskirtų pirmus tris “Y” stulpelio elementus.
Užrašykite komandą, kuri iš matricos
mišskirtų nelyginius pirmo stulpelio narius išdėstytus mažėjimo tvarka.
Veiksmai su matricomis
Algebriniai veiksmai su matricomis yra atliekami taip pat kaip ir su vektoriais - paelemenčiui. Išnaudojant tokio tipo skaičiavimus R kalboje galima atlikti tokių operacijų su matricomis, kurių įvadiniame tiesinės algebros kurse nerasite.
Pavyzdžiui, galima atlikti “matricų dalybą”.
Arba pavyzdžiui matricų daugybą paelemenčiui.
Kodas
C * R
#> [,1] [,2]
#> [1,] 1 12
#> [2,] 6 28
#> [3,] 15 48
#> [4,] 28 72
#> [5,] 45 100Žinoma, tipinės matricų algebros operacijos yra aprašytos ir R kalboje: matricų daugybą, determinanto skaičiavimas, atvirkštinės matricos radimas, transponavimas. Šie veiksmai aprašyti žemiau esančioje lentelėje.
| Operacija |
R funkcija / operatorius |
Pavyzdys (A, B – suderintos matricos) |
|---|---|---|
| Matricų sandauga | %*% |
C <- A %*% B |
| Transponavimas | t() |
At <- t(A) |
| Determinantas | det() |
det(A) |
| Atvirkštinė matrica | solve() |
A_inv <- solve(A) |
Duota lygčių sistemos koeficientų matrica \(A\) ir laisvųjų narių vektorius \(b\). Išspręskite lygčių sistemą.
\(A = \begin{pmatrix} 1 & 0 & -1 \\ 3 & -2 & -2 \\ 1 & -2 & 1 \end{pmatrix}, \,\,\) \(b = (2, 1, 1)^T\).
\(A = \begin{pmatrix} 1 & 1 & 3 \\ 1 & -1 & -1 \\ 3 & -2 & -1 \end{pmatrix}, \,\,\) \(b = (3, 1, 4)^T\).
Kodas
# 1.
A <- matrix(c(1, 0, -1,
3, -2, -2,
1, -2, 1), nrow = 3, byrow = T)
b <- c(2, 1, 1)
solve(A) %*% b
#> [,1]
#> [1,] 6.0
#> [2,] 4.5
#> [3,] 4.0
# 2.
A <- matrix(c(1, 1, 3,
1, -1, -1,
3, -2, -1), nrow = 3, byrow = T)
b <- c(3, 1, 4)
solve(A) %*% b
#> Error in solve.default(A): sistema yra skaičiuojant singuliari: atvirkštinis sąlygos skaičius = 5.55112e-18Vektorių ir matricų apjungimas
Vektorių apjungimui į vektorių naudojama funkcija c(), o norint apjungti vektorius į matricą arba vektorius su matricomis - naudojamos funkcijos cbind() ir rbind().
Funkcija cbind() sujungia vektorius kaip matricos stulpelius, o rbind() - kaip eilutes.
Pavyzdžiui, apjungsime du vektorius į matricą pagal stulpelius.
Gautos matricos stulpelių vardai sutampa su vektorių vardais. Jeigu reikia pakeisti stulpelių vardus, tai galima naudoti funkciją colnames() arba galima nurodyti stulpelių pavadinimus vektorių apjungimo metu.
Jeigu apjungiamų vektorių ilgiai nesutampa, trumpesnis yra cikliškai pratęsiamas.
Kodas
cbind(1, 5:10)
#> [,1] [,2]
#> [1,] 1 5
#> [2,] 1 6
#> [3,] 1 7
#> [4,] 1 8
#> [5,] 1 9
#> [6,] 1 10Kaip minėta skyrelio pradžioje, *bind funkcijos pritaikomos ir matricoms. Tarkime, apjungsime matricą pagal stulpelius su pačia savimi ir pridėsime papildomą stulpelį.
Kodas
m_su_m <- cbind(m_pagal_c, 5*m_pagal_c, "Grupė" = rep(1:2, 2))
m_su_m
#> Endogeninis Egzogeninis Endogeninis Egzogeninis Grupė
#> [1,] 2.6 3.5 13.0 17.5 1
#> [2,] 4.8 2.9 24.0 14.5 2
#> [3,] 6.3 6.2 31.5 31.0 1
#> [4,] 8.1 18.9 40.5 94.5 2
#> [5,] 11.0 31.5 55.0 157.5 1
#> [6,] 13.0 14.1 65.0 70.5 2Pastebėkite, jog stulpelių vardai gali kartotis. Renkantis stulpelį pagal pavadinimą, bus parenkamas pirmas iš eilės stulpelis su tokiu vardu.
Kodas
m_su_m[, "Endogeninis"]
#> [1] 2.6 4.8 6.3 8.1 11.0 13.0Dimensijos išlaikymas
Jeigu iš matricos pasirenkame vieną eilutę ar stulpelį, tai tokio veiksmo rezultatas yra vektorius.
Kodas
m_pagal_c[, 2]
#> [1] 3.5 2.9 6.2 18.9 31.5 14.1
class(m_pagal_c[, 2])
#> [1] "numeric"Jeigu norime, kad rezultatas turėtų dimensijų atributą ir būtų grąžinamas kaip vienos eilutės ar stulpelio matrica, reikia nurodyti pasirinkimo metu argumentą drop = FALSE.
Kodas
m_pagal_c[, 2, drop = FALSE]
#> Egzogeninis
#> [1,] 3.5
#> [2,] 2.9
#> [3,] 6.2
#> [4,] 18.9
#> [5,] 31.5
#> [6,] 14.1
class(m_pagal_c[, 2, drop = FALSE])
#> [1] "matrix" "array"Pagal nutylėjimą argumento reikšmė yra drop = TRUE.
3.3 Sąrašas
Iki šiol nagrinėtos duomenų struktūros apsiribojo tuo, kad elementai turi būti vienodo tipo. R kalboje skirtingų tipų objektus galima apjungti į sąrašą (list). Sąrašą galima tapatinti su Python kalbos žodynu.
Techniškai, sąrašas yra vektorius. Iki šiol nagrinėti paprasti vektoriai laikomi atominiais vektoriais, nes jų nebegalima išskaidyti į dar smulkesnes struktūras. Tuo tarpu sąrašas yra vadinamas rekursyviuoju vektoriumi, nes jo elementai gali būti kiti sąrašai, t.y. struktūra gali kartotis per kelis lygius.
Sąrašai naudojami kaip talpyklos. Vieno sąrašo elementai gali būti įvairios duomenų struktūros: vektoriai, matricos, sąrašai, duomenų lentelės ir t. t.
Norint sukurti sąrašą naudojama funkcija list(), kurios argumentai - vienas po kito einantys sąrašo elementai.
Išvestyje dvigubuose laužtiniuose skliaustuose nurodyti sąrašo elementai, pvz. pirmas sąrašo elementas [[1]].
Tokia duomenų struktūra yra specialaus tipo.
Kodas
class(s)
#> [1] "list"Funkciją length() taip pat galima naudoti ir su sąrašu - bus grąžinamas sąrašo elementų skaičius.
Kodas
length(s)
#> [1] 4Sąrašo elementams galima suteikti vardus taip pat kaip vektoriaus elementams - arba naudojant funkciją names(), arba sąrašo sudarymo metu.
Kaip ir kiti R objektai, sąrašas taip pat gali turėti atributus, kuriuos peržiūrai naudojama funkcija attributes().
Kodas
attributes(s)
#> $names
#> [1] "skaičiai" "NA" "logika" "matrica"Jeigu sąrašas yra sudėtingos hierarchinės struktūros, galima ją peržiūrėti neišvedant pačio sąrašo elementų. Tam taikoma str() funkcija.
Kodas
str(s)
#> List of 4
#> $ skaičiai: num [1:2] 0 3.14
#> $ NA : chr NA
#> $ logika : logi [1:3] FALSE TRUE FALSE
#> $ matrica : int [1:2, 1:2] 1 2 3 4Sąrašo elementų išrinkimas
Tam tikram sąrašo elementui pasiekti yra keli operatoriai: $, [], [[]].
Jeigu reikia pasirinkti konkretų vieną sąrašo elementą ir jį grąžinti tikruoju tipu, naudojami dvigubi laužtiniai skliaustai [[]], kuriuose įrašomas arba elemento vardas, arba jo indeksas. Jeigu sąrašo elementas turi vardą, galima jį tiesiogiai pasiekti naudojant $ simbolį, po kurio seka elemento pavadinimas (be kabučių).
Kodas
s[[3]]
#> [1] FALSE TRUE FALSE
s[["logika"]]
#> [1] FALSE TRUE FALSE
s$logika
#> [1] FALSE TRUE FALSEGrąžinami elementai bus pradiniu tipu.
Kodas
class(s$logika)
#> [1] "logical"Jeigu reikia pasirinkti kelis sąrašo elementus, t.y. tam tikrą sąrašo poaibį, tai naudojami viengubi laužtiniai skliaustai [], kurių viduje įrašomi sąrašo elementų indeksai arba jų vardai.
Kodas
s[1:2]
#> $skaičiai
#> [1] 0.000000 3.141593
#>
#> $`NA`
#> [1] NA
class(s[1:2])
#> [1] "list"Žinoma, galima pasirinkti poaibį sudarytą iš vieno elemento, tačiau vis vien grąžinamas objektas bus sąrašas.
Kodas
s["logika"]
#> $logika
#> [1] FALSE TRUE FALSE
class(s["logika"])
#> [1] "list"Elementų išrinkimo iš sąrašo atvejus apibūdina žemiau esanti lentelė.
| Tikslas | Sintaksė | Rezultatas | Pastabos |
|---|---|---|---|
| Gauti vieną elementą jo pradiniu tipu |
lst$vardaslst[["vardas"]]lst[[i]]
|
Reikšmė (skaičius, vektorius, sąrašas …) | Naudoja dvigubus skliaustus arba $; indeksas i – skaičius |
| Gauti vieną ar kelis elementus kaip posąrašį |
lst["vardas"]lst[i]
|
Sąrašas | Naudoja viengubus skliaustus; grąžina visada sąrašą, net jei pasirenkate tik vieną elementą |
Vienoje išraiškoje galima derinti skirtingus operatorius - [, [[ ir $. Tai ypač praverčia, kai sąrašas yra sudėtingos hierarchijos ir reikia pasiekti giliai esantį objektą. Daugelio statistinių procedūrų grąžinamas rezultatas būna sąrašas, kuriame gali būti kitų sąrašų, o šių elementai - vektoriai, matricos ir pan.
Pavyzdžiui, iš sąrašo s išskirsime antrą pirmojo elemento (vektoriaus) narį.
Kodas
s[[1]][2] # [[ … ]] ištraukia sąrašo elementą, [ … ] – vektoriaus narį
#> [1] 3.141593
s[["skaičiai"]][2] # tas pats, bet sąrašo elementas imamas vardu
#> [1] 3.141593
s$skaičiai[2] # trumpa forma su $ ir vardo nurodymu
#> [1] 3.141593Sukurkite sąrašą, kuris turi du elementus: pirmas elementas yra vektorius iš mažųjų lotyniškų raidžių, o antras - iš to vektoriaus padaryta matrica su dviem stulpeliais. Sąrašo elementams suteikite vardus “vektorius” ir “matrica”.
Naudokite sąrašą iš 1-os užduoties ir išrinkite balses iš pirmojo ir iš antrojo sąrašo elementų.
Užrašykite komandą, kuri išrinktų pirmą ir paskutinį sąrašo
selementus, nepaisant sąrašo ilgio.Iš sąrašo
sišskirkite paskutinio elemento paskutinį elementą. Parašykite komandą taip, kad nepriklausytų nuo sąrašo ilgio.
Kodas
# 1.
s1 <- list("vektorius" = letters, "matrica" = matrix(letters, ncol = 2))
s1
#> $vektorius
#> [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
#> [20] "t" "u" "v" "w" "x" "y" "z"
#>
#> $matrica
#> [,1] [,2]
#> [1,] "a" "n"
#> [2,] "b" "o"
#> [3,] "c" "p"
#> [4,] "d" "q"
#> [5,] "e" "r"
#> [6,] "f" "s"
#> [7,] "g" "t"
#> [8,] "h" "u"
#> [9,] "i" "v"
#> [10,] "j" "w"
#> [11,] "k" "x"
#> [12,] "l" "y"
#> [13,] "m" "z"
# 2.
s1$vektorius[c(1, 5, 9, 21, 25)]
#> [1] "a" "e" "i" "u" "y"
c(s1[[2]][c(1, 5, 9), 1], s1[[2]][c(2, 8, 12), 2])
#> [1] "a" "e" "i" "o" "u" "y"
# 3.
s[c(1, length(s))]
#> $skaičiai
#> [1] 0.000000 3.141593
#>
#> $matrica
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
# 4.
s[[length(s)]][ nrow(s[[length(s)]]), ncol(s[[length(s)]]) ]
#> [1] 4Elementų pridėjimas, ištrynimas, sąrašo redagavimas
Pasirinkus konkretų sąrašo elementą galima jį ištrinti priskiriant reikšmę NULL. Šiuo atveju galima pasirinkima atlikti bet kokiu būdu.
Kodas
# tinka ir $, ir [], ir [[]]
s[2] <- NULL
s
#> $skaičiai
#> [1] 0.000000 3.141593
#>
#> $logika
#> [1] FALSE TRUE FALSE
#>
#> $matrica
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4Svarbu atkreipti dėmesį, jog ištrynus sąrašo elementą, likusių elementų indeksai pasikeičia.
Norint pridėti naują vieną sąrašo elementą galima tiesiog pasirinktai naujai pozicijai arba naujam vardui priskirti norimą reikšmę.
Kodas
s$zodis <- "laba"
s[5] <- "diena"
s[[7]] <- "studentai"
s
#> $skaičiai
#> [1] 0.000000 3.141593
#>
#> $logika
#> [1] FALSE TRUE FALSE
#>
#> $matrica
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
#>
#> $zodis
#> [1] "laba"
#>
#> [[5]]
#> [1] "diena"
#>
#> [[6]]
#> NULL
#>
#> [[7]]
#> [1] "studentai"Pastebėkite, jog priskiriant reikšmę indeksui, kuris nėra sekantis po paskutinio, tarp jų esantiems indeksams priskiriamos NULL reikšmės.
Taip pat galima sąrašus apjungti su funkcija c().
Pavyzdyje prijungiamas sąrašas (antras) turi elementą su tokiu pat pavadinimu “zodis”. Kas nutiks su pradinio sąrašo s elementu “zodis” naujame sąraše s_added? Kas bus grąžinama, jeigu išsirinktume šį elementą iš sąrašo s_added?
Kai reikia redaguoti sąrašo elementus, patogu naudoti funkciją modifyList().
| Argumentas | Reikšmė |
|---|---|
x |
Pradinis sąrašas, galimas ir tuščias. |
val |
sąrašas, kurio elementus pridedame į x arba perrašome x reikšmes. |
keep.null |
Jei TRUE, elementai, kurių nauja reikšmė NULL, paliekami (neišmetami) |
Pavyzdžiui prie sąrašo lst pridėsime naują, vardą turintį, elementą.
Kodas
lst <- list("praleista" = NA, 1:10, FALSE)
lst.mod1 <- modifyList(lst, list("parametrai" = c(1, 5)))Tarkime, norime redaguoti sąrašo elemento praleista reikšmę, pakeičiant į 0.
Kodas
modifyList(lst, list("praleista" = 0))
#> $praleista
#> [1] 0
#>
#> [[2]]
#> [1] 1 2 3 4 5 6 7 8 9 10
#>
#> [[3]]
#> [1] FALSEŠią funkciją galima išnaudoti ir elementų šalinimui. Pavyzdžiui, pašalinsime iš pradinio lst sąrašo elementą praleista.
Kodas
modifyList(lst, list("praleista" = NULL))
#> [[1]]
#> [1] 1 2 3 4 5 6 7 8 9 10
#>
#> [[2]]
#> [1] FALSESąrašų apjungimas
Tarkime, kad turime du sąrašus a ir b.
Jau žinote, jog galima apjungti kelis sąrašus į vieną sąrašą naudojant funkciją c(). Gauto sąrašo ilgis yra lygus apjungiamų sąrašų elementų skaičiui.
Kodas
s.c <- c(a, b)Į vieną sąrašą apjungti kelis sąrašus galima ir su funkcija list(). Tačiau esminis skirtumas tas, kad gautas sąrašas bus rekursyvus, t.y. elementai bus sąrašai. Kitap tariant, gaunamas kelių lygių sąrašas.
Kodas
s.list <- list("pirmas" = a, "antras" = b)
s.list
#> $pirmas
#> $pirmas[[1]]
#> [1] 0 1 0 1
#>
#> $pirmas[[2]]
#> [1] 80 15 20 27 88
#>
#> $pirmas[[3]]
#> [1] 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
#> [16] 0.75 0.80 0.85 0.90 0.95 1.00
#>
#>
#> $antras
#> $antras[[1]]
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20Tokio sąrašo ilgis yra jį sudarančių sąrašų skaičius.
Kodas
length(s.list)
#> [1] 2Pasirenkamas sąrašo pirmo elemento pirmo vektoriaus pirmas narys.
Kodas
s.list$pirmas[[1]][1]
#> [1] 0Sąrašo struktūrą galima supaprastinti apjungiant jį sudarančius elementus į vektorių. Tam naudojama funkcija unlist().
| Argumentas | Reikšmė |
|---|---|
x |
Pradinis sąrašas, kurio struktūra supaprastinama. |
recursice |
loginis (TRUE), nurodo sąrašo elementus apjungti rekursiškai |
keep.null |
loginis (TRUE), nurodo sąrašo elementams išlaikyti vardus |
Iš vieno sąrašo su 4 elementais gaunamas vienas vektorius.
Kodas
unlist(s.c)
#> [1] 0.00 1.00 0.00 1.00 80.00 15.00 20.00 27.00 88.00 0.00 0.05 0.10
#> [13] 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
#> [25] 0.75 0.80 0.85 0.90 0.95 1.00 1.00 2.00 3.00 4.00 5.00 6.00
#> [37] 7.00 8.00 9.00 10.00 11.00 12.00 13.00 14.00 15.00 16.00 17.00 18.00
#> [49] 19.00 20.00Pritaikius funkciją kelių lygių sąrašui taip pat gaunamas vienas vektorius. Kadangi sąrašas turėjo vardus, tai gauto vektoriaus elementai bus su vardais. Parinkus argumentą use.names = FALSE, vardai išvesties vektoriuje neišsaugomi.
Kodas
unlist(s.list)
#> pirmas1 pirmas2 pirmas3 pirmas4 pirmas5 pirmas6 pirmas7 pirmas8
#> 0.00 1.00 0.00 1.00 80.00 15.00 20.00 27.00
#> pirmas9 pirmas10 pirmas11 pirmas12 pirmas13 pirmas14 pirmas15 pirmas16
#> 88.00 0.00 0.05 0.10 0.15 0.20 0.25 0.30
#> pirmas17 pirmas18 pirmas19 pirmas20 pirmas21 pirmas22 pirmas23 pirmas24
#> 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
#> pirmas25 pirmas26 pirmas27 pirmas28 pirmas29 pirmas30 antras1 antras2
#> 0.75 0.80 0.85 0.90 0.95 1.00 1.00 2.00
#> antras3 antras4 antras5 antras6 antras7 antras8 antras9 antras10
#> 3.00 4.00 5.00 6.00 7.00 8.00 9.00 10.00
#> antras11 antras12 antras13 antras14 antras15 antras16 antras17 antras18
#> 11.00 12.00 13.00 14.00 15.00 16.00 17.00 18.00
#> antras19 antras20
#> 19.00 20.00
unlist(s.list, use.names = FALSE)
#> [1] 0.00 1.00 0.00 1.00 80.00 15.00 20.00 27.00 88.00 0.00 0.05 0.10
#> [13] 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
#> [25] 0.75 0.80 0.85 0.90 0.95 1.00 1.00 2.00 3.00 4.00 5.00 6.00
#> [37] 7.00 8.00 9.00 10.00 11.00 12.00 13.00 14.00 15.00 16.00 17.00 18.00
#> [49] 19.00 20.00Jeigu reikia atsisakyti hierarchinės kelių lygių sąrašo struktūros, galima naudoti funkciją unlist(), nustačius argumentą recursive = FALSE. Tuomet funkcija suprastina sąrašo struktūrą ne iki pačios minimaliausios (vektoriaus), o iki vieno lygio sąrašo.
Kodas
unlist(s.list, recursive = FALSE)
#> $pirmas1
#> [1] 0 1 0 1
#>
#> $pirmas2
#> [1] 80 15 20 27 88
#>
#> $pirmas3
#> [1] 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
#> [16] 0.75 0.80 0.85 0.90 0.95 1.00
#>
#> $antras
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20Sukurkite sąrašą
defaults, kurio elementai yrabg = "white",font = 1,cex = 1. Pakeiskite sąrašo elementųfontircexreikšmes naudodami ir nenaudodami funkcijosmodifyList()Užrašykite kaip galima trumpesnę komandą, kuri sukurtų sąrašą, sudarytą iš 10 \(2\times 2\) dydžio matricų, kurios pirmo stulpelio elementai lygūs 1, o antro - 2.
Užrašykite kuo trumpesnę 2 užduoties komandą taip, kad eilučių skaičius būtų parametrizuotas (užfiksuotas iš anksto).
Duotas sąrašas
w <- list(list(list(1:2), list(3:4)), list(list(5:6), list(7:8))). Išnagrinėkite ir nubrėžkite schematiškai jo struktūrą. Kiek elementų sudaro šį sąrašą?Funkcija
unlist(w)iš sąrašo padaro vektorių. Gaukite tokį patį vektorių su funkcijaunlist(), tačiau su parametrurecursive = FALSE.
Kodas
# 1.
defaults <- list(bg = "white", font = 1, cex = 1)
modifyList(defaults, list(cex = 0.8, font = 5))
#> $bg
#> [1] "white"
#>
#> $font
#> [1] 5
#>
#> $cex
#> [1] 0.8
defaults$font <- 0.2
defaults$cex <- 2
defaults
#> $bg
#> [1] "white"
#>
#> $font
#> [1] 0.2
#>
#> $cex
#> [1] 2
# 2.
rep(list(matrix(c(1, 1, 2, 2), 2)), 10)
#> [[1]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[2]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[3]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[4]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[5]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[6]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[7]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[8]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[9]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#>
#> [[10]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
# 3.
i <- 10
rep(list(cbind(rep(1, i), rep(2, i))), 10)
#> [[1]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[2]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[3]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[4]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[5]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[6]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[7]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[8]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[9]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
#>
#> [[10]]
#> [,1] [,2]
#> [1,] 1 2
#> [2,] 1 2
#> [3,] 1 2
#> [4,] 1 2
#> [5,] 1 2
#> [6,] 1 2
#> [7,] 1 2
#> [8,] 1 2
#> [9,] 1 2
#> [10,] 1 2
# 4.
w <- list(list(list(1:2), list(3:4)), list(list(5:6), list(7:8)))
str(w)
#> List of 2
#> $ :List of 2
#> ..$ :List of 1
#> .. ..$ : int [1:2] 1 2
#> ..$ :List of 1
#> .. ..$ : int [1:2] 3 4
#> $ :List of 2
#> ..$ :List of 1
#> .. ..$ : int [1:2] 5 6
#> ..$ :List of 1
#> .. ..$ : int [1:2] 7 8
length(w)
#> [1] 2
# 5.
unlist(unlist(unlist(w, recursive = F), recursive = F), recursive = F)
#> [1] 1 2 3 4 5 6 7 83.4 Duomenų lentelė
Norint suprasti, kodėl duomenų lentelės (data frame) R kalboje yra tokios svarbios, pravartu iš eilės peržvelgti, kaip didėja duomenų struktūrų sudėtingumas.
Pirmiausia turime atomines reikšmes - pavienius skaičius, simbolius, datas. Kai jų prireikia daugiau, sudarome atominius vektorius, o jei reikia dar dvimatės struktūros - naudojame matricas, kurios leidžia greitai laikyti didelius kiekius vienodo tipo duomenų.
Susidūrus su mišriomis reikšmėmis (pvz., skaičiai, tekstai, datos vienoje grupėje) prireikia sąrašų, nes juose kiekvienas elementas gali būti bet ko tipo, net kitas sąrašas. Tačiau kai heterogeniškus kintamuosius norime aprašyti „lentelės“ forma, kur kiekviena eilutė – vieno stebėjimo vieneto įrašai, o kiekvienas stulpelis turi savo tipą, sąrašas tampa nepatogiu formatu.
Šioje vietoje atsiranda duomenų lentelė: iš esmės tai sąrašas, kurio visi elementai yra vienodo ilgio vektoriai, todėl vienu metu užtikrinama ir stulpelių tipų įvairovė, ir kiekvienos eilutės vientisumas. Šis apribojimas paverčia nevienalytį sąrašą duomenų lentele, suteikdamas \(eilute \times stulpelis\) struktūrą ir išsaugodamas kiekvieno stulpelio pradinį tipą.
Taip logiškai keliaudami nuo atominių vektorių per sąrašus pasiekiame duomenų lentelės struktūrą.
Žemiau pateikta iliustracija perteikia panašumus ir skirtumus R kalboje naudojamų duomenų struktūrų.
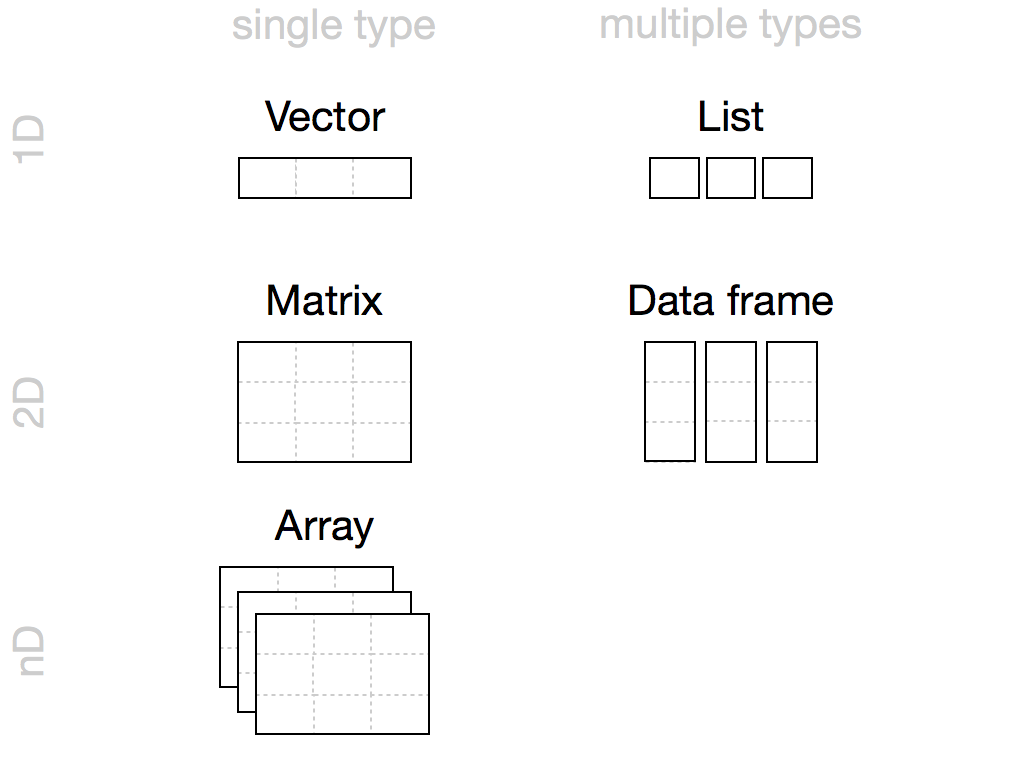
Duomenų struktūrų sąsajos
3.4.1 Duomenų lentelės sukūrimas
Kaip ir kitiems duomenų tipams, duomenų lentelės sukūrimui naudojama specifinė funkcija data.frame(), kurios parametrai - vienodo ilgio vektoriai.
Sukursime duomenų lentelę df, sudarytą iš trijų kintamųjų.
Kodas
studentai <- c("Jonas", "Petras", "Agnė")
amzius <- c(18, 20, 19)
aktyvus <- c(TRUE, FALSE, TRUE)
df <- data.frame(studentai, amzius, aktyvus)
df
#> studentai amzius aktyvus
#> 1 Jonas 18 TRUE
#> 2 Petras 20 FALSE
#> 3 Agnė 19 TRUEKaip matome, duomenų lentelės išvestis atrodo lygiai taip pat kaip ir matricos su stulpelių pavadinimais. Šį kartą stulpelių pavadinimai atitinka vektorių pavadinimus. Kad tai tikrai nėra matrica, įsitikinti galima patikrinus objekto klasę.
Kodas
class(df)
#> [1] "data.frame"Duomenų lentelės struktūrą - kintamųjų pavadinimus, jų kiekį, tipus, stebinių skaičių - galima patikrinti su funkcija str().
Kodas
str(df)
#> 'data.frame': 3 obs. of 3 variables:
#> $ studentai: chr "Jonas" "Petras" "Agnė"
#> $ amzius : num 18 20 19
#> $ aktyvus : logi TRUE FALSE TRUEKadangi duomenų lentelė kaip ir matrica yra dvimatės struktūros, tai galima patikrinti jos dimensijas.
Duomenų lentelės kintamųjų vardus parodo funkcija names().
Kodas
names(df)
#> [1] "studentai" "amzius" "aktyvus"Šią funkciją galima naudoti ir kintamųjų vardų pakeitimui.
Duomenų lentelės eilučių vardus parodo funkcija row.names(). Pagal nutylėjimą eilutės sunumeruojamos ir eilučių vardai išsaugojimo kaip character tipo.
Kodas
row.names(df)
#> [1] "1" "2" "3"Pati primityviausia duomenų lentelė turi keletą pagrindinių atributų - kintamųjų vardai, eilučių pavadinimai ir lentelės klasė.
Kodas
attributes(df)
#> $names
#> [1] "vardas" "metai" "statusas"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3Kai kurios duomenų lentelėms ir matricoms naudojamos funkcijos yra specifinės: vienos iš jų tinka lentelėms, bet netaikomos matricoms ir atvirkščiai. Gali būti, kad tam tikrais atvejais funkcijos rezultatas gali turėti kitokią prasmę. Funkcija length() apskaičiuoja vektorių, matricų ir sąrašų elementų skaičių. Jei funkcijos length() argumentas bus duomenų lentelė, rezultatas bus jos stulpelių skaičius. Tai galima paaiškinti tuo, kad duomenų lentelės elementai yra vienodo ilgio sąrašo elementai, o sąrašo ilgis - elementų skaičius.
Kodas
length(df)
#> [1] 3Sukurkite duomenų lentelę
zmones, sudarytą iš trijų stulpelių. Pirmas stulpelis vardas ir pavardė, antras - lytis, o trečias - koks nors kiekybinis kintamasis, pvz., amžius, atlyginimas, ūgis.Naudodami funkciją
names()pakeiskite kintamųjų vardus.Naudodami funkciją
row.names()pakeiskite eilučių vardus.
Kodas
# 1.
col1 <- c("Petras Petrauskas", "Algimantas Algimantauskas", "Jonas J.")
col2 <- c("V", "V", "M")
col3 <- c(25, 50, 82)
zmones <- data.frame(col1, col2, col3)
zmones
#> col1 col2 col3
#> 1 Petras Petrauskas V 25
#> 2 Algimantas Algimantauskas V 50
#> 3 Jonas J. M 82
# 2.
names(zmones) <- c("vardas", "lytis", "metai")
zmones
#> vardas lytis metai
#> 1 Petras Petrauskas V 25
#> 2 Algimantas Algimantauskas V 50
#> 3 Jonas J. M 82
# 3.
rownames(zmones) <- c("svarbus", "svarbesnis", "svarbiausias")
zmones
#> vardas lytis metai
#> svarbus Petras Petrauskas V 25
#> svarbesnis Algimantas Algimantauskas V 50
#> svarbiausias Jonas J. M 823.4.2 Kintamųjų išskyrimas
Kadangi duomenų lentelė iš esmės yra sąrašas, tai jos elementus galima pasiekti taip pat kaip ir sąrašo elementus.
df[[1]]
df[["vardas"]]
df$vardasSvarbu nepamiršti, jog naudojant [] arba [[]] grąžinami skirtingos klasės objektai. Naudojant viengubus laužtinius skliaustus išskiriant duomenų lentelės elementus (stulpelius), grąžinama klasė yra duomenų lentelė.
Kadangi duomenų lentelė turi dimensijos atributą, galima jos elementus išskirti taip pat kaip matricos elementus.
Kodas
df[, 1] # pirmas stulpelis (kintamasis)
#> [1] "Jonas" "Petras" "Agnė"
df[1, ] # pirma eilultė (stebinys)
#> vardas metai statusas
#> 1 Jonas 18 TRUEIšskirti galima ir pagal eilutės arba stulpelio vardą, jeigu tik tokie yra suteikti.
Kodas
df[, "vardas"]
#> [1] "Jonas" "Petras" "Agnė"Tam tikro duomenų lentelės poaibio išskyrimas yra lengvai atliekamas naudojant matricų elementų išskyrimo sintaksę.
Kodas
df[c(1, 3), 1:2]
#> vardas metai
#> 1 Jonas 18
#> 3 Agnė 19Nurodžius neigiamą indeksą, elementas nepasirenkamas.
Kodas
df[-1, -2]
#> vardas statusas
#> 2 Petras FALSE
#> 3 Agnė TRUEIš lentelės
dfišskirkite antrąjį stulpelį naudodami: stulpelio numerį, jo vardą, operatorius[,[[ir$.Iš lentelės
dfsukurkite naują lentelę, kurioje neliktų dviejų paskutinių eilučių. Kaip tai padaryti naudojant ne eilučių numerius, o jų vardus?Naudojant kintamųjų numerius sukeiskite vietomis pirmus du lentelės
dfstulpelius. Tą pati atlikite naudodami kintamųjų vardus.Sukurkite tokį indeksą, kurį naudojant iš lentelės
dfbūtų išrenkamos visos eilutės su nelyginiais numeriais.Sukurkite tokį indeksą, kuris iš lentelės
dfišskirtų eilutes, kuriose kintamasisstatusasįgyją reikšmęTRUE.
Kodas
# 1.
# naudojant stulpelio numerį
df[, 2]
#> [1] 18 20 19
df[2]
#> metai
#> 1 18
#> 2 20
#> 3 19
df[[2]]
#> [1] 18 20 19
# naudojant stulpelio vardą
df[, "metai"]
#> [1] 18 20 19
df["metai"]
#> metai
#> 1 18
#> 2 20
#> 3 19
df[["metai"]]
#> [1] 18 20 19
df$metai
#> [1] 18 20 19
# 2.
df_subset <- df[1:(nrow(df)-2), ]
# 3.
df[, c(2:1, 3)]
#> metai vardas statusas
#> 1 18 Jonas TRUE
#> 2 20 Petras FALSE
#> 3 19 Agnė TRUE
df[, c("metai", "vardas", "statusas")]
#> metai vardas statusas
#> 1 18 Jonas TRUE
#> 2 20 Petras FALSE
#> 3 19 Agnė TRUE
# 4.
nelygines_eilutes <- seq(1, nrow(df), by = 2)
# arba
nelygines_eilutes <- as.logical(1:nrow(df) %% 2)
df[nelygines_eilutes, ]
#> vardas metai statusas
#> 1 Jonas 18 TRUE
#> 3 Agnė 19 TRUE
# 5.
i <- df$statusas == TRUE
df[i, ]
#> vardas metai statusas
#> 1 Jonas 18 TRUE
#> 3 Agnė 19 TRUE
# arba trumpiau
df[df$statusas == TRUE, ]
#> vardas metai statusas
#> 1 Jonas 18 TRUE
#> 3 Agnė 19 TRUEFunkcijos subset() ir complete.cases()
Kartais duomenų rinkiniai turi praleistų reikšmių. Jeigu reikia išskirti eilutes naudojant logines sąlygas pagal kintamuosius, kurie turi NA reikšmių, tos eilutės su NA irgi yra grąžinamos.
Kodas
df_na <- data.frame(
vardas = c("Aida", "Tomas", "Inga", "Dainius"),
balas = c(4.5, NA, 3.2, 4.1)
)
indeksas <- df_na$balas > 4
df_na[indeksas, ]
#> vardas balas
#> 1 Aida 4.5
#> NA <NA> NA
#> 4 Dainius 4.1Paprasčiausias būdas kaip to išvengti, tai pridėti dar vieną salygą prie kintamojo, jog būtų išmetamos visos NA reikšmės.
Kodas
indeksas <- df_na$balas > 4 & !is.na(df_na$balas)
df_na[indeksas, ]
#> vardas balas
#> 1 Aida 4.5
#> 4 Dainius 4.1Tačiau jeigu loginė sąlygą susidėtų iš daug kintamųjų, kurių kiekvienas gali turėti po bent vieną NA reikšmę, toks sprendimas pasidaro nepraktiškas. Patogiau naudoti universalią funkciją subset(). Funkcija yra universali, nes pritaikoma skirtingoms klasės objektams. Pavyzdžiui, taikant funkciją su duomenų lentelėmis galimi keli arugmentai išvardyti žemiau.
| Argumentas | Reikšmė |
|---|---|
x |
duomenų lentelė |
subset |
loginė sąlyga, nurodanti, kurias eilutes palikti |
select |
išraiška, nurodanti, kuriuos stulpelius palikti |
Ši funkcija patogi tuo, kad pagal nutylėjimą argumentas subset visas NA reikšmes tikrinamoje sąlygoje laiko kaip FALSE, dėl to, tokie įrašai yra neįtraukiami.
Kodas
subset(df_na, balas > 4)
#> vardas balas
#> 1 Aida 4.5
#> 4 Dainius 4.1Kita pravarti funkcija dirbant su NA reikšmėmis yra complete.cases(). Funkcija grąžina loginį vektorių, kur TRUE reikšmė atitinka eilutę, kuri neturi NA reikšmių, t.y. visi kintamieji eilutėje yra užpildyti.
Kodas
cc <- complete.cases(df_na) # loginis vektorius
df_na[cc, ] # paliekame tik pilnų duomenų eilutes
#> vardas balas
#> 1 Aida 4.5
#> 3 Inga 3.2
#> 4 Dainius 4.13.4.3 Duomenų lentelių apjungimas
Dėl duomenų lentelės panašumų ir į matricą ir į sąrašą, yra keletas skirtingų būdų kaip pridėti naują kintamąjį.
Pavyzdžiui, galima pridėti naują kintamąjį nurodant naujo stulpelio numerį arba jo vardą. Toks būdas atitiktų matricos naujo stulpelio pridėjimą.
Kodas
df[, 4] <- rep("keisti statusą", 3)
df
#> vardas metai statusas V4
#> 1 Jonas 18 TRUE keisti statusą
#> 2 Petras 20 FALSE keisti statusą
#> 3 Agnė 19 TRUE keisti statusą
df[, "pastaba"] <- rep("keisti statusą", 3)
df
#> vardas metai statusas V4 pastaba
#> 1 Jonas 18 TRUE keisti statusą keisti statusą
#> 2 Petras 20 FALSE keisti statusą keisti statusą
#> 3 Agnė 19 TRUE keisti statusą keisti statusąAnalogiškai sąrašams, naujo elemento (kintamojo) pridėjimas į duomenų lentelę atliekamas su operatoriumi [], nurodant numerį arba vardą, arba naudojant $ operatorių su nurodytų vardu.
Kodas
df[6] <- 1 # išnaudojama cikliškumo savybė
df
#> vardas metai statusas V4 pastaba V6
#> 1 Jonas 18 TRUE keisti statusą keisti statusą 1
#> 2 Petras 20 FALSE keisti statusą keisti statusą 1
#> 3 Agnė 19 TRUE keisti statusą keisti statusą 1
df$naujas_kintamasis <- "string"
df
#> vardas metai statusas V4 pastaba V6 naujas_kintamasis
#> 1 Jonas 18 TRUE keisti statusą keisti statusą 1 string
#> 2 Petras 20 FALSE keisti statusą keisti statusą 1 string
#> 3 Agnė 19 TRUE keisti statusą keisti statusą 1 stringJeigu norime sukurti keletą naujų kintamųjų, galima išnaudoti duomenų lentelės panašumus su sąrašu. Nurodomas naujų vardų vektorius pasirinkimo metu ir atitinkamai kintamiesiems priskiriamos sąrašo reikšmės.
Kodas
df[c("A", "B", "C")] <- list(c(1, 10, 100), "reikšmė", NA)
df
#> vardas metai statusas V4 pastaba V6 naujas_kintamasis A
#> 1 Jonas 18 TRUE keisti statusą keisti statusą 1 string 1
#> 2 Petras 20 FALSE keisti statusą keisti statusą 1 string 10
#> 3 Agnė 19 TRUE keisti statusą keisti statusą 1 string 100
#> B C
#> 1 reikšmė NA
#> 2 reikšmė NA
#> 3 reikšmė NAPaprasčiausias būdas kaip pašalinti kintamąjį - reikia jam priskirti NULL reikšmę.
Kodas
df[, 4] <- NULL
df[, "pastaba"] <- NULL
df[6] <- NULL
df$naujas_kintamasis <- NULLKai reikia pašalinti kelis kintamuosius vienu metu, jiems reikia priskirti NULL objektą.
Naudodami operatorių
[]anksčiau sudarytoje lentelėjezmonessukurkite naują kintamąjį N, kurio visos reikšmės būtų lygios 0.Naudodami operatorių
$lentelėjezmonessukurkite kintamąjį X, kurio visos reikšmės praleistos. Nekuriant iš naujo kintamojo X, paskutinę jo reikšmę pakeiskite į 100.Lentelėje
zmonespanaikinkite paskutinius du kintamuosius.
Kodas
# 1.
zmones["N"] <- 0
zmones
#> vardas lytis metai N
#> svarbus Petras Petrauskas V 25 0
#> svarbesnis Algimantas Algimantauskas V 50 0
#> svarbiausias Jonas J. M 82 0
# 2.
zmones$X <- NA
zmones[nrow(zmones), "X"] <- 100
zmones
#> vardas lytis metai N X
#> svarbus Petras Petrauskas V 25 0 NA
#> svarbesnis Algimantas Algimantauskas V 50 0 NA
#> svarbiausias Jonas J. M 82 0 100
# 3.
m <- ncol(zmones)
zmones[(m-1):m] <- NULLPanašiai kaip ir matricas, naudojant funkciją cbind(), vieną lentelę galima prijungti prie kitos lentelės šono. Tokiu atveju abiejų lentelių eilučių skaičius turi būti vienodas.
Kodas
a <- data.frame(A = 10:15, B = TRUE)
b <- data.frame(A = 6:1, B = FALSE)
m <- cbind(a, b)
m
#> A B A B
#> 1 10 TRUE 6 FALSE
#> 2 11 TRUE 5 FALSE
#> 3 12 TRUE 4 FALSE
#> 4 13 TRUE 3 FALSE
#> 5 14 TRUE 2 FALSE
#> 6 15 TRUE 1 FALSENaudojant funkciją cbind(), prie lentelės kaip naują kintamąjį galima prijungti ir vektorių. Pvz., taip sukursime naują lentelės df kintamąjį I, kurio visos reikšmės bus lygios 1. Kadangi prijungiamas vektorius yra trumpesnis, jo reikšmės pakartojamos.
Kodas
df <- cbind(df, I = 1)
df
#> vardas metai statusas V6 I
#> 1 Jonas 18 TRUE 1 1
#> 2 Petras 20 FALSE 1 1
#> 3 Agnė 19 TRUE 1 1Naudojant funkciją rbind(), duomenų lentelės apjungiamos sudedant jas vieną ant kitos. Šiuo atveju būtina, kad kintamųjų vardai abiejose lentelėse sutaptų, tačiau eilučių skaičius gali būti bet koks.
Kodas
m <- rbind(a, b)
m
#> A B
#> 1 10 TRUE
#> 2 11 TRUE
#> 3 12 TRUE
#> 4 13 TRUE
#> 5 14 TRUE
#> 6 15 TRUE
#> 7 6 FALSE
#> 8 5 FALSE
#> 9 4 FALSE
#> 10 3 FALSE
#> 11 2 FALSE
#> 12 1 FALSENaudodami funkciją
cbind()anksčiau sudarytoje lentelėjezmonessukurkite naują kintamąjįN, kurio visos reikšmės būtų lygios nuliui.Sukurkite tokius pačius kintamuosius turinčią lentelę
k, kuri turėtų tik vieną eilutę, ir prijunkite ją prie lentelėszmonesapačios.
Kodas
# 1.
zmones <- cbind(zmones, "N" = 0)
zmones
#> vardas lytis metai N
#> svarbus Petras Petrauskas V 25 0
#> svarbesnis Algimantas Algimantauskas V 50 0
#> svarbiausias Jonas J. M 82 0
# 2.
k <- data.frame(vardas = "Vardenis P.", lytis = "V", metai = NA, N = 0)
zmones <- rbind(zmones, k)
zmones
#> vardas lytis metai N
#> svarbus Petras Petrauskas V 25 0
#> svarbesnis Algimantas Algimantauskas V 50 0
#> svarbiausias Jonas J. M 82 0
#> 1 Vardenis P. V NA 0